Cloud Logging: долгосрочное хранение и анализ


На сегодняшний день Yandex Cloud Logging предоставляет возможность хранения логов в течение 3 дней. И даже если срок хранения расширят до месяца, это все равно не будет покрывать многие сценарии. Так как же организовать долгосрочное хранение логов? Для этого нам понадобится создать Data Stream, лог группу, которая будет в него писать, а так же Data Transfer, которы сможет перекладывать данные в какое-то долгосрочное хранилище. В этом примере я буду использовать Yandex Cloud Object Storage (аналог AWS S3). Это самый дешевый из возможных вариантов, при этом обеспечивающий не только хранение, но и с выходом Yandex Queryи возможность анализа хранимых логов.
А теперь давайте по порядку.
Создаем инфраструктуру
Создадим serverless базу YDB
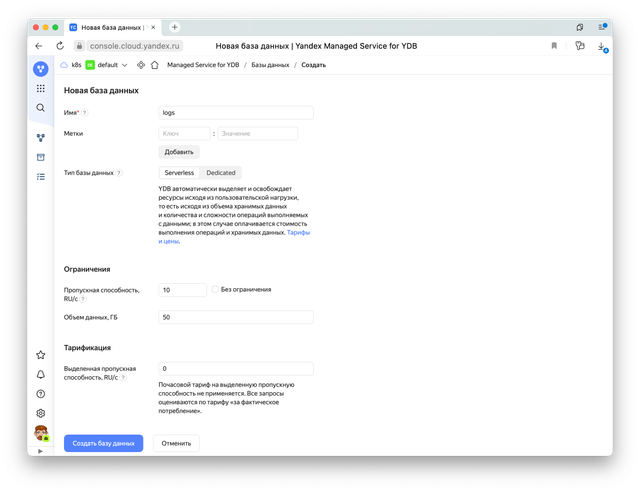
Она нам понадобится для того, чтобы в ней создать поток Data Stream.
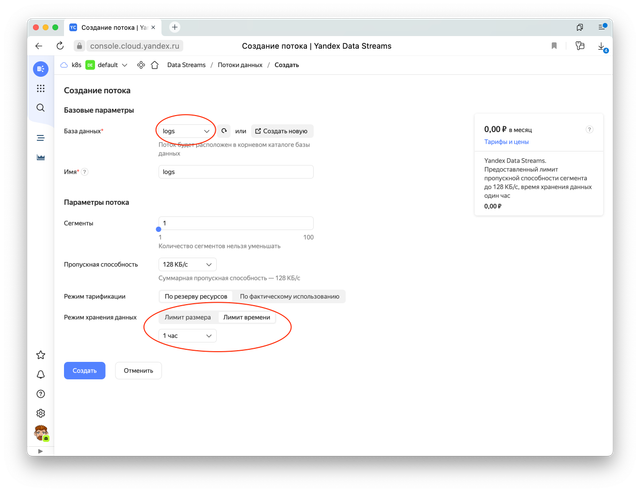
В параметрах укажем только что созданную базу. Если же выбрать минимальную конфигурацию потока, то он может быть вообще бесплатным, но не более одного такого потока привязанного к платежному аккаунту, далее платно.
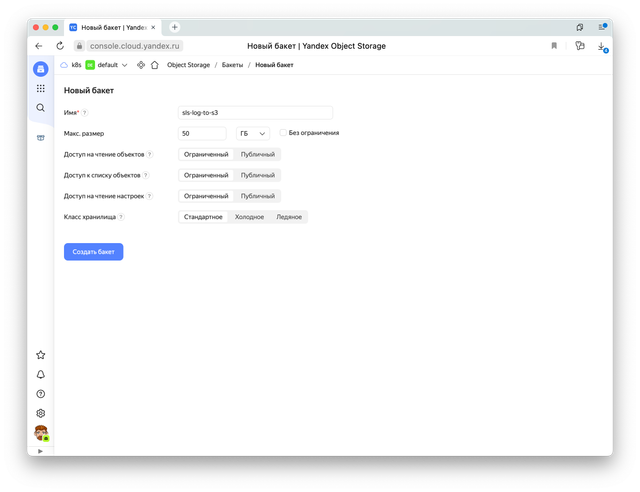
Теперь создадим бакет, куда мы будем писать логи.
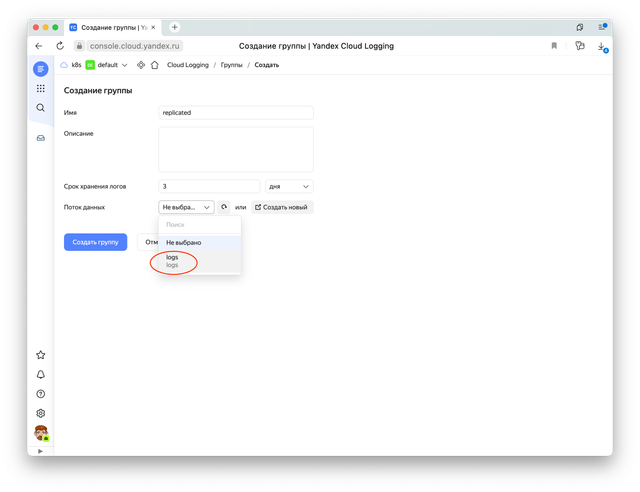
Теперь можно создать лог-группу в сервисе Cloud Logging. Ее мы сможем указывать в функции, serverless контейнере, API Gateway или любом другом месте откуда мы собираемся писать логи.
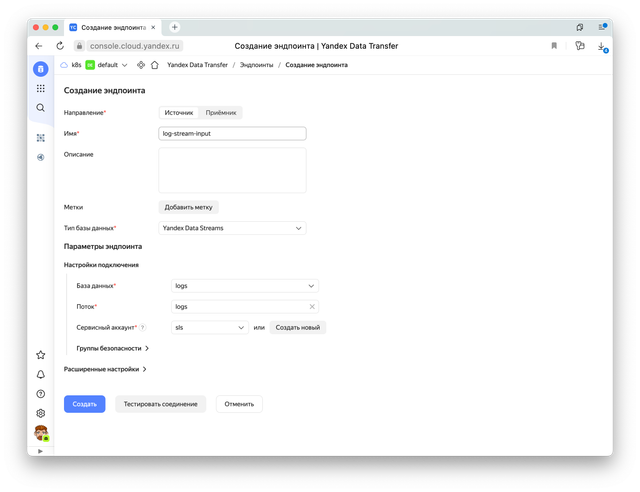
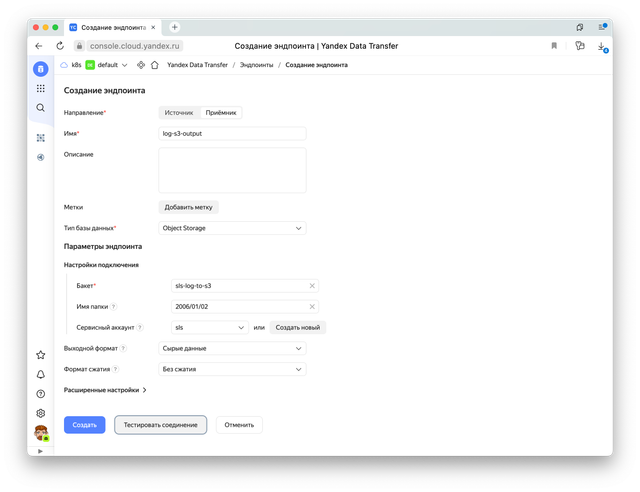
Теперь нам нужно создать эндпоинты Data Transfer: источник данных из стрима logs и приемник данных — наш бакет sls-log-to-s3.
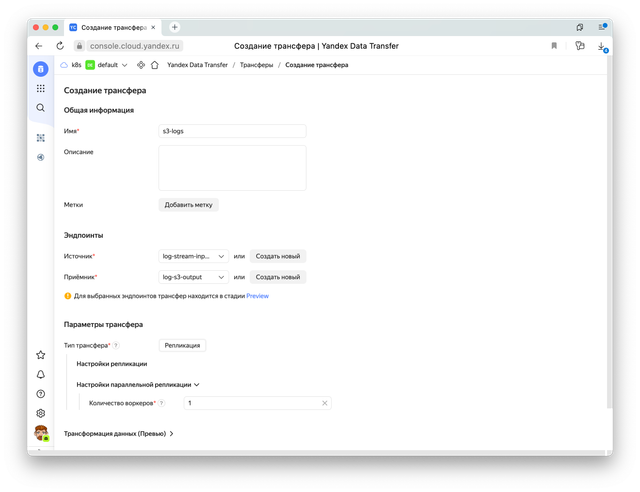
А теперь объединить их в трансфер.
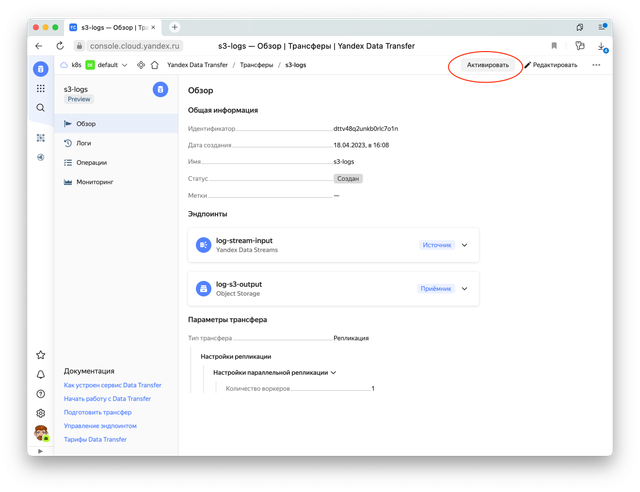
Теперь трансфер нужно активировать.
Вот в принципе и все. Теперь остается только создать функцию, передать в нее ло�г-группу и погенерировать логов, чтобы убедиться, что всё работает.
import logging
import random
from pythonjsonlogger import jsonlogger
class YcLoggingFormatter(jsonlogger.JsonFormatter):
def add_fields(self, log_record, record, message_dict):
super(YcLoggingFormatter, self).add_fields(log_record, record, message_dict)
log_record['logger'] = record.name
log_record['level'] = str.replace(str.replace(record.levelname, "WARNING", "WARN"), "CRITICAL", "FATAL")
logHandler = logging.StreamHandler()
logHandler.setFormatter(YcLoggingFormatter('%(message)s %(level)s %(logger)s'))
logger = logging.getLogger('MyLogger')
logger.propagate = False
logger.addHandler(logHandler)
logger.setLevel(logging.DEBUG)
def handler(event, context):
val = random.random()
if val > .8:
logger.error("some error log", extra={"val": val})
elif val > .5:
logger.info("test logging", extra={"val": val})
else:
logger.debug("everything is fine", extra={"val": val})
return {
'statusCode': 200,
'body': 'Hello World!',
}
И в requirements.txt добавить python-json-logger==2.0.4
Анализ
Теперь перейдя в бакет мы можем увидеть, что логи туда успешно реплицируются.
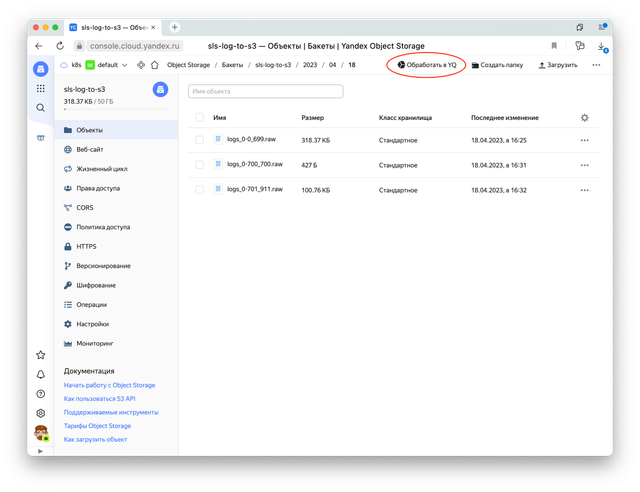
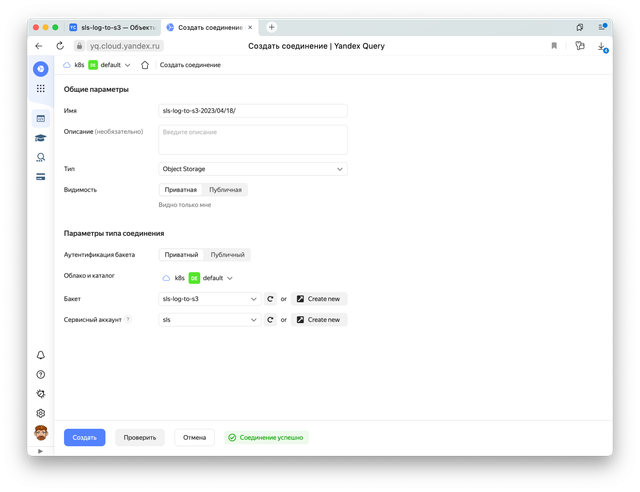
Давайте теперь попробуем проанализировать их при помощи Yandex Query. Для этого создадим новое соединение, нажав на кнопку «Обработать в YQ».
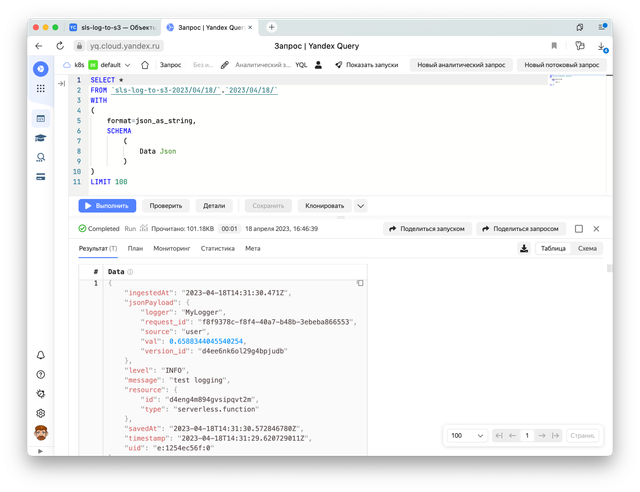
SELECT *
FROM `sls-log-to-s3-2023/04/18/`.`2023/04/18/`
WITH
(
format=json_as_string,
SCHEMA
(
Data Json
)
)
LIMIT 100
Тут мы указываем, что будем обращаться к созданному ранее источнику `sls-log-to-s3–2023/04/18/` по пути `2023/04/18/`. Таким образом YQ возьмет все файлы за день и будет использовать данные из них при выполнении запроса.
Далее мы указываем формат json_as_string. Подробнее про форматы можно прочитать в документации.
Отлично, теперь мы видим, шейп данных.
Для того чтобы обратиться к вложенным полям JSON-объекта мы будем использовать JSON_VALUE. К сожалению напрямую в GROUP BY его мы использовать не можем, но можем завернуть извлечение данных в подзапрос, а группировку вынести выше.
Вот пример чуть более сложного запроса с аггрегациями.
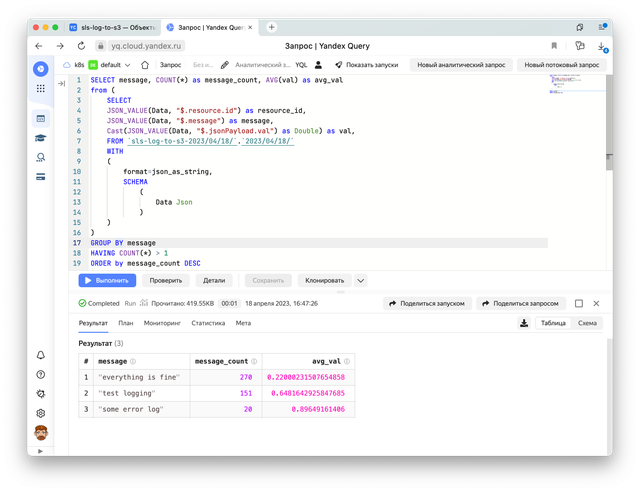
SELECT message, COUNT(*) as message_count, AVG(val) as avg_val
FROM (
SELECT
JSON_VALUE(Data, "$.resource.id") as resource_id,
JSON_VALUE(Data, "$.message") as message,
Cast(JSON_VALUE(Data, "$.jsonPayload.val") as Double) as val,
FROM `sls-log-to-s3-2023/04/18/`.`2023/04/18/`
WITH (
format=json_as_string,
SCHEMA(
Data Json
)
)
)
GROUP BY message
HAVING COUNT(*) > 1
ORDER by message_count DESC
В завершении хочу добавить, что вы можете также настроить политики хранения данных в Object Storage, чтобы перекладывать старые логи по истечении какого-то времени в другие классы хранения или вообще удалять их.