Traefik как WAF
· 6 мин. чтения


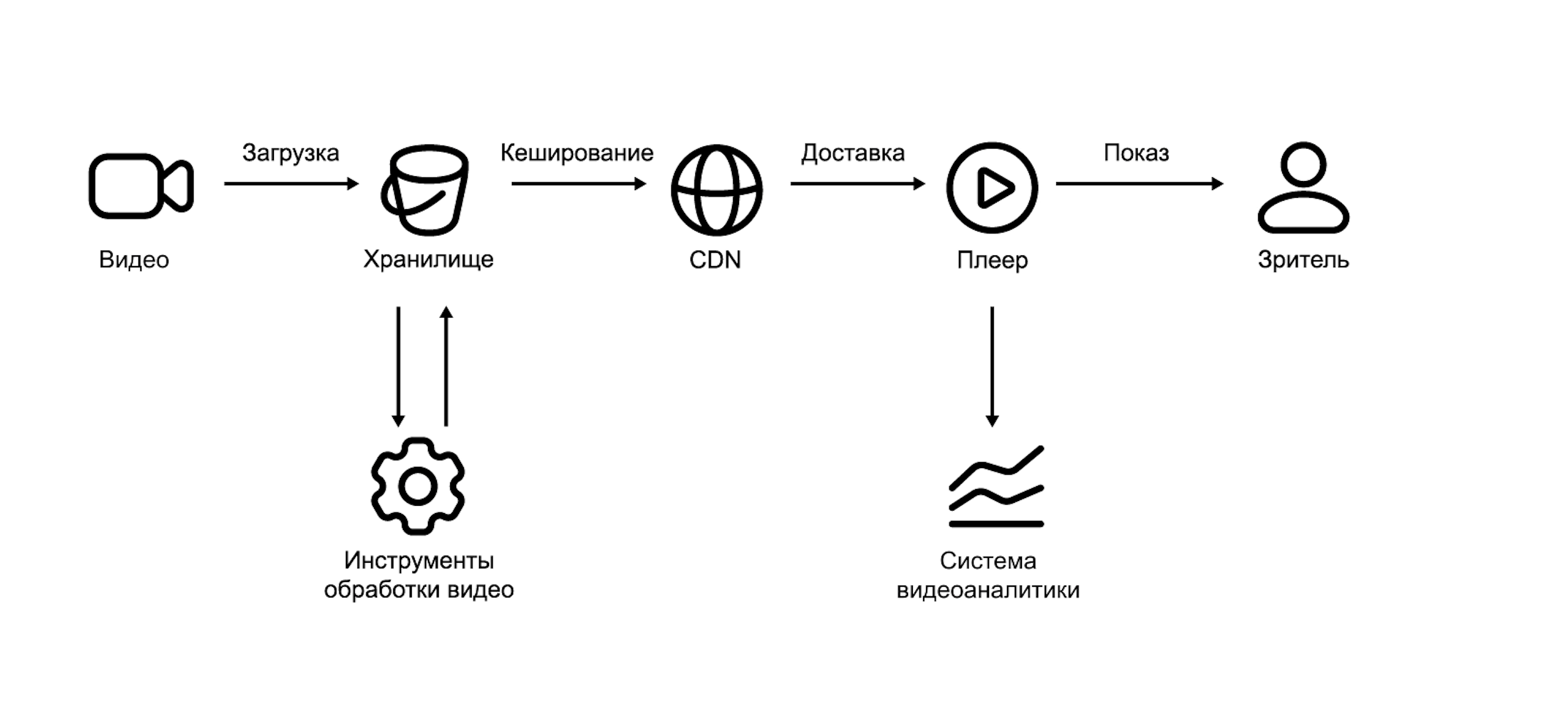
WAF (Web Application Firewall) — это инструмент, который защищает веб-приложения от различных видов атак, анализируя и фильтруя HTTP-запросы. Вот основные преимущества и случаи, когда WAF может быть полезен:
Отдельным плюсом является возможность использования WAF без изменения кода приложения. WAF работает как промежуточное звено между пользователем и сервером, поэтому разработчикам не нужно вносить изменения в код приложения. Это экономит время и снижает вероятность ошибок.
Однако, библиотека про которую пойдет речь в этой статье, Coraza, также может быть использована внутри приложения.

 В прошлом
В прошлом