Обработка отложенных задач в YDB: от таблицы до распределённого координатора


Почти любой бэкенд рано или поздно сталкивается с необходимостью отложенной обработки задач: отправить email после регистрации, пересчитать агрегаты, выполнить задачу по расписанию. Часто для этого подключают отдельную систему — RabbitMQ, Kafka, Redis-очереди. Но если ваши данные уже живут в YDB, нужные примитивы уже рядом: таблицы, changefeed, топики и координационные ноды.
В этой статье разберём четыре подхода к асинхронной обработке задач — от простой таблицы до архитектуры, пригодной для production-сценариев. Каждый следующий подход решает проблемы предыдущего, но добавляет сложности. Вместо абстрактных описаний — рабочий код на Go с использованием ydb-go-sdk.
Подход 1. Таблица как очередь задач
Самый простой способ организовать очередь — записать задачу в таблицу, а потом опросить её консьюмером.
Схема
CREATE TABLE tasks (
id UUID NOT NULL,
payload String NOT NULL,
created_at Timestamp NOT NULL,
done_at Timestamp,
PRIMARY KEY (id)
);
Колонка done_at пустая у необработанных задач. Консьюмер отбирает строки с done_at IS NULL, выполняет работу и записывает время завершения.
Продюсер
Продюсер генерирует задачи и вставляет их через UPSERT:
pool := pond.NewPool(*parallelism,
pond.WithContext(ctx),
pond.WithQueueSize(*parallelism),
)
for {
err := pool.Go(func() {
id := uuid.New()
payload := generatePayload(*payloadSize)
db.Query().Exec(ctx,
`UPSERT INTO tasks (id, payload, created_at)
VALUES ($id, $payload, $created_at)`,
query.WithParameters(
ydb.ParamsBuilder().
Param("$id").Uuid(id).
Param("$payload").Bytes(payload).
Param("$created_at").Timestamp(time.Now()).
Build(),
),
)
})
if err != nil {
break // пул остановлен (Ctrl-C)
}
}
Пул воркеров из библиотеки pond ограничивает параллелизм. WithContext(ctx) останавливает пул при отмене контекста (например, по Ctrl-C), а WithQueueSize держит буфер задач на уровне параллелизма, чтобы продюсер не накапливал в памяти миллионы ожидающих задач.
Каждый воркер выполняет одну вставку и возвращается в пул. Параметризованные запросы с $id, $payload, $created_at защищают от SQL-инъекций и позволяют YDB кэшировать план запроса.
Реальный код продюсера также собирает простую телеметрию: атомарные счётчики totalRows, totalBytes, totalDuration. В конце он печатает rows/sec, throughput в Mbps и среднюю задержку вставки — этого достаточно, чтобы подбирать параметры -parallelism и -payload-size на практике.
Зачем UPSERT, а не INSERT
UPSERT (INSERT OR REPLACE) — идемпотентная операция. Если запрос завершился с сетевой ошибкой и клиент не знает, выполнилась ли вставка, он может безопасно повторить — результат будет тот же. Для очередей задач это важное свойство: повторная запись задачи не создаст дубликат.
Когда этого достаточно
- Задачи не срочные, задержка в секунды приемлема
- Один или несколько консьюмеров с простой логикой
- Объём задач невелик (единицы тысяч в минуту)
Ограничения
Polling. Консьюмер должен периодически опрашивать таблицу (SELECT ... WHERE done_at IS NULL). Между вставкой и обработкой всегда есть пауза, равная интервалу опроса.
Hotspot. Все консьюмеры конкурируют за одни и те же строки. При высоком параллелизме это приведёт к конфликтам транзакций.
Нет порядка. Таблица с UUID в качестве первичного ключа не гарантирует порядок обработки. Нет приоритетов, нет FIFO.
Нет push-уведомлений. Консьюмер не узнает о новой задаче, пока не спросит.
А что, если база сама могла бы уведомлять о новых задачах?
Подход 2. CDC — реактивная обработка через changefeed
YDB умеет отслеживать изменения таблицы и публиковать их в топик. Этот механизм называется Change Data Capture (CDC). Достаточно добавить changefeed на существующую таблицу — и каждый INSERT автоматически становится сообщением в топике.
Настройка
ALTER TABLE tasks ADD CHANGEFEED cdc_tasks WITH (
FORMAT = 'JSON',
MODE = 'NEW_IMAGE'
);
MODE = 'NEW_IMAGE' означает, что в сообщение попадёт полный образ строки после изменения. Продюсер из предыдущего примера продолжает писать в таблицу tasks как раньше — его код не меняется вообще. Но теперь каждая вставка автоматически порождает CDC-событие.
Консьюмер
CDC-консьюмер подключается к топику через Topic API:
reader, err := db.Topic().StartReader(
*consumer,
topicoptions.ReadTopic(topicPath),
)
И читает сообщения пакетами в бесконечном цикле:
for {
batch, err := reader.ReadMessagesBatch(ctx)
if err != nil { ... }
for _, msg := range batch.Messages {
// Парсим CDC-событие
var cdc cdcMessage
json.Unmarshal(data, &cdc)
// DELETE-события пропускаем (newImage пуст)
if len(cdc.NewImage) == 0 {
continue
}
// Извлекаем ID задачи из ключа
rowID, _ := uuid.Parse(cdc.Key[0])
// Эмулируем полезную работу
time.Sleep(*workDelay)
// Помечаем задачу выполненной
db.Query().Exec(ctx,
`UPSERT INTO tasks (id, payload, created_at, done_at)
VALUES ($id, '', $created_at, CurrentUtcTimestamp())`,
query.WithParameters(
ydb.ParamsBuilder().
Param("$id").Uuid(rowID).
Param("$created_at").Timestamp(createdAtTime).
Build(),
),
)
}
// Коммитим оффсет всего пакета
reader.Commit(ctx, batch)
}
Формат CDC-событий
Каждое CDC-сообщение — JSON:
{
"key": ["550e8400-e29b-41d4-a716-446655440000"],
"newImage": {
"id": "550e8400-e29b-41d4-a716-446655440000",
"payload": "...",
"created_at": "2026-03-31T12:00:00.000000Z"
}
}
Для INSERT-событий поле update отсутствует, для UPDATE/DELETE оно присутствует. Для DELETE дополнительно newImage будет null или пустым. Консьюмер фильтрует события по len(newImage) == 0, отбрасывая удаления и оставляя INSERT/UPDATE.
Гарантии доставки
Паттерн at-least-once: читаем пакет → обрабатываем все сообщения → коммитим оффсет. Если консьюмер упал между обработкой и коммитом, при перезапуске он перечитает тот же пакет. Именно поэтому операция завершения использует UPSERT, а не UPDATE — повторная запись тех же данных идемпотентна.
Consumer groups обеспечивают отслеживание прогресса: при перезапуске консьюмер продолжит с последнего закоммиченного оффсета.
В примере выше обработка ошибок опущена, чтобы не перегружать код. В рабочей версии каждая стадия проверяется отдельно: json.Unmarshal, uuid.Parse, UPSERT и Commit.
Для мониторинга консьюмер обновляет атомарные счётчики processed, skipped и errors, а фоновая goroutine раз в секунду печатает их в логах. Это важно, потому что оффсет пакета коммитится вне зависимости от ошибок отдельных сообщений: иначе одна сбойная запись могла бы остановить всю партицию.
У такого решения есть важная цена: сообщение с ошибкой больше не будет автоматически перечитано. Для best-effort задач это часто приемлемо — например, если событие обновляет метрику, кеш, вторичный индекс или другое состояние, которое можно пересчитать. Но для критичных бизнес-операций такой подход может быть плохой идеей. Он не подойдёт для биллинга, платежей, юридически значимых событий, необратимых внешних вызовов и задач, где потеря одной записи хуже, чем временная остановка обработки.
В таких сценариях ошибки стоит разделять на два класса:
- Временные сбои: недоступна база, упал внешний сервис, истёк timeout. В этом случае оффсет лучше не коммитить, чтобы Topic API доставил сообщение повторно после рестарта или ретрая.
- Некорректные сообщения: битый JSON, неизвестная версия схемы, невалидный payload. Их лучше перекладывать в отдельную таблицу или DLQ с исходным payload, причиной ошибки и временем сбоя, а оффсет коммитить только после успешной записи в DLQ.
Если важен строгий порядок внутри партиции, даже DLQ может быть недостаточно: пропуск одного сообщения позволит следующим обогнать его. Тогда лучше останавливать обработку партиции, поднимать alert и разбирать проблему вручную. Если нужны retry с backoff, счётчик попыток и явный статус каждой задачи, стоит переходить к подходу 4 с таблицей задач и координированными воркерами.
Что решает CDC
- Push вместо polling. Консьюмер получает события в реальном времени, без задержки опроса.
- Нулевые изменения в продюсере. Changefeed — это дополнение к таблице, а не замена. Существующий код записи не нужно менять.
- Встроенная устойчивость. Topic API сам управляет переподключениями и ретраями.
Ограничения CDC
Нет контроля партицирования. Партиции CDC-топика определяются шардированием таблицы, а не бизнес-логикой. Вы не можете гарантировать, что все задачи одного пользователя попадут в одну партицию.
Конфликты при чтении и обновлении одной строки. Если консьюмеру нужно обновлять общее состояние (например, счётчик per-user), параллельные консьюмеры могут конфликтовать на одной строке.
Привязка к схеме. Формат changefeed повторяет структуру таблицы. Если вам нужен другой формат сообщений, придётся преобразовывать на стороне консьюмера.
Для полного контроля маршрутизации сообщений нужно писать в топики напрямую.
Подход 3. Topic API — контроль партицирования
CDC даёт push-модель, но забирает контроль над распределением сообщений. Прямая запись через Topic API возвращает контроль: вы сами решаете, в какую партицию попадёт каждое сообщение.
Зачем контролировать партицирование
Предположим, консьюмер инкрементирует счётчик для каждого пользователя — классическая read-modify-write (RMW) операция. Если сообщения одного пользователя разбросаны по разным партициям, несколько консьюмеров одновременно попытаются обновить одну строку. В YDB это приводит к Transaction Level Incompatibility (TLI) — транзакция откатывается и повторяется.
Решение — маршрутизировать сообщения так, чтобы все данные одного пользователя попадали в одну партицию и обрабатывались одним консьюмером.
Архитектура
Продюсер пишет в топик напрямую, привязывая writer к конкретной партиции:
func hashKey(key string, partitions int) int64 {
return int64(murmur3.Sum64([]byte(key)) % uint64(partitions))
}
// По одному writer на партицию
writers := make([]*safeWriter, partitions)
for i := range writers {
w, _ := db.Topic().StartWriter(topicPath,
topicoptions.WithWriterPartitionID(int64(i)),
topicoptions.WithWriterWaitServerAck(true),
)
writers[i] = &safeWriter{w: w}
}
// Маршрутизация: hash(key) → partition
key := msg.UserID.String()
partitionIdx := hashKey(key, partitions)
writers[partitionIdx].write(ctx, data)
murmur3.Sum64 — быстрая хеш-функция с хорошим распределением. WithWriterPartitionID привязывает writer к физической партиции. WithWriterWaitServerAck(true) гарантирует, что сообщение записано на сервере перед возвратом.
Консьюмер читает по одной горутине на партицию:
for i := 0; i < partitionCount; i++ {
go func(partitionID int) {
reader, _ := db.Topic().StartReader(
consumerName,
topicoptions.ReadSelectors{
{Path: topic, Partitions: []int64{int64(partitionID)}},
},
)
for {
msg, _ := reader.ReadMessage(ctx)
workload(ctx, benchMsg)
reader.Commit(ctx, msg)
}
}(i)
}
Бенчмарк: как ключ влияет на конфликты транзакций
Пример запускает четыре сценария на одних и тех же данных:
| Ключ партицирования | Что делает консьюмер | Ожидаемый результат |
|---|---|---|
| by_user (по пользователю) | Читает и обновляет счётчик пользователя | TLI ≈ 0 |
| by_user | Только вставляет ID обработанного сообщения | TLI = 0 |
| by_message_id (случайное) | Читает и обновляет счётчик пользователя | Много TLI |
| by_message_id | Только вставляет ID обработанного сообщения | TLI = 0 |
Первая и третья строки — это read-modify-write: serializable-транзакция читает текущее значение счётчика, прибавляет е диницу и записывает результат обратно.
func statsWorkload(db *ydb.Driver, tliCounter *atomic.Int64) func(context.Context, BenchMessage) error {
return func(ctx context.Context, msg BenchMessage) error {
attempt := 0
return db.Query().DoTx(ctx, func(ctx context.Context, tx query.TxActor) error {
if attempt > 0 {
tliCounter.Add(1) // считаем ретрай как TLI
}
attempt++
return tx.Exec(ctx,
`UPSERT INTO stats
SELECT
r.user_id AS user_id,
COALESCE(t.a, 0) + r.a AS a,
COALESCE(t.b, 0) + r.b AS b,
COALESCE(t.c, 0) + r.c AS c
FROM AS_TABLE($records) AS r
LEFT JOIN stats AS t ON r.user_id = t.user_id`,
query.WithParameters(...),
)
}, query.WithTxSettings(
query.TxSettings(query.WithSerializableReadWrite()),
))
}
}
Вставка без чтения — UPSERT INTO processed (id) VALUES ($id). Нет предшествующего чтения — нет конфликта, TLI всегда ноль.
Почему это работает

Когда ключ партицирования совпадает с ключом данных (user_id), все операции над одним пользователем выполняются
последовательно в одной горутине. Нет параллельного доступа — нет TLI.

Когда ключ — случайный message_id, данные одного пользователя разбрасываются по всем 10 партициям.
10 горутин конкурируют за одну строку в таблице stats — TLI растёт пропорционально числу консьюмеров.
Вывод: на практике выбор ключа партицирования часто оказывается самой эффективной оптимизацией для снижения числа конфликтов транзакций.
Ограничения подхода
Нет управления задачами. Топики — это потоки сообщений, не очереди. Нет приоритетов, нет retry с backoff, нет отложенного запуска.
Ручное назначение партиций. В этом примере каждый reader явно привязан к конкретному partitionID. Если reader для одной из 10 партиций упадёт и приложение не поднимет новый reader с тем же selector, эта партиция перестанет обрабатываться.
Это ограничение конкретной схемы benchmark-а, а не Topic API в целом. В обычной схеме с несколькими reader-ами на весь topic YDB может балансировать партиции между клиентами. Здесь мы сознательно отказываемся от этой гибкости ради детерминированного соответствия «партиция → goroutine».
Fire-and-forget. После коммита оффсета нет способа узнать, в каком состоянии задача — она просто «прочитана».
Для полноценной очереди задач с приоритетами, отложенным запуском и распределённой координацией нужна другая архитектура.
Подход 4. Координированные воркеры с таблицей задач
Этот подход объединяет таблицу (для хранения состояния задач) с координационными нодами YDB (для распределения работы между воркерами). Результат — система, которая поддерживает приоритеты, отложенный запуск, восстановление после сбоев и динамическую ребалансировку.
В репозитории реализация разделена на два независимых приложения — cmd/producer и cmd/worker — поверх общих пакетов pkg/taskproducer, pkg/taskworker, pkg/rebalancer, pkg/metrics. Ниже показаны фрагменты из этих пакетов.
Таблица задач
CREATE TABLE coordinated_tasks (
id Utf8 NOT NULL,
hash Int64 NOT NULL,
partition_id Uint16 NOT NULL,
priority Uint8 NOT NULL,
status Utf8 NOT NULL, -- pending | locked | completed
payload Utf8 NOT NULL,
lock_value Utf8,
locked_until Timestamp,
scheduled_at Timestamp,
created_at Timestamp NOT NULL,
done_at Timestamp,
PRIMARY KEY (partition_id, priority, id)
);
Составной первичный ключ (partition_id, priority, id) — ключевое проектное решение:
- partition_id как префикс позволяет эффективно сканировать задачи одной партиции
- priority на втором месте обеспечивает
ORDER BY priority DESCбез дополнительного индекса - id гарантирует уникальность
256 логических партиций — это не партиции YDB-таблицы. Это уровень приложения: partition_id = murmur3.Sum32(task_id) % 256 (32-битный вариант с маской знакового бита, чтобы получить положительный остаток после преобразования в int64). Каждый воркер владеет подмножеством этих логических партиций и обрабатывает только «свои» задачи.
Продюсер
Продюсер вставляет задачи с контролируемой скоростью. Вместо вставки по одной строке он работает в fixed-window batch-режиме: на каждом окне (по умолчанию 100 мс) собирает batch из targetBatchSize = rate * batchWindow задач и пишет их одним UPSERT-ом через AS_TABLE:
func buildBatch(ctx context.Context, batchSize int, partitions int, apigwURL string) []taskRow {
rows := make([]taskRow, 0, batchSize)
for range batchSize {
taskID, _ := uid.GenerateUUID()
hash := int64(murmur3.Sum32([]byte(taskID)))
partitionID := uint16(uint64(hash&0x7FFFFFFFFFFFFFFF) % uint64(partitions))
priority := uint8(rand.Intn(256))
payload := fmt.Sprintf(`{"url":"https://%s/"}`, apigwURL)
now := time.Now().UTC()
var scheduledAt *time.Time
if rand.Intn(10) == 0 { // ~10% — отложенный запуск
t := now.Add(time.Duration(5+rand.Intn(26)) * time.Second)
scheduledAt = &t
}
rows = append(rows, taskRow{ /* поля */ })
}
return rows
}
func upsertBatch(ctx context.Context, db *ydb.Driver, batch []taskRow) error {
records := make([]types.Value, 0, len(batch))
for _, r := range batch {
records = append(records, types.StructValue(
types.StructFieldValue("id", types.TextValue(r.id)),
types.StructFieldValue("hash", types.Int64Value(r.hash)),
types.StructFieldValue("partition_id", types.Uint16Value(r.partitionID)),
types.StructFieldValue("priority", types.Uint8Value(r.priority)),
types.StructFieldValue("payload", types.TextValue(r.payload)),
types.StructFieldValue("created_at", types.TimestampValueFromTime(r.createdAt)),
types.StructFieldValue("scheduled_at", types.NullableTimestampValueFromTime(r.scheduledAt)),
))
}
return db.Query().Exec(ctx,
`UPSERT INTO coordinated_tasks
SELECT id, hash, partition_id, priority, "pending"u AS status,
payload, created_at, scheduled_at
FROM AS_TABLE($records)`,
query.WithParameters(
ydb.ParamsBuilder().
Param("$records").Any(types.ListValue(records...)).
Build(),
),
)
}
Главный цикл собирает batch, выполняет upsertBatch, замеряет длительность записи и спит остаток окна. Если upsert не уложился в окно, инкрементируется счётчик Backpressure: это сигнал, что целевая скорость не достигнута.
Такой режим даёт стабильный rate с погрешностью в единицы процентов и амортизирует round-trip к YDB по сотням строк.
Полезная нагрузка задачи — JSON вида {"url":"https://<apigw>/"}. В реальном цикле обработки воркер делает HTTP POST по этому URL. API Gateway здесь используется как удобная HTTP-мишень для нагрузки, а статусы ответов учитываются Prometheus-счётчиком.
Распределение партиций: Coordination API
Как 3 воркера делят 256 партиций без конфликтов? С помощью координационных нод YDB.
Coordination node — это распределённый сервис, предоставляющий эфемерные семафоры. Для каждой из 256 логических партиций создаётся exclusive-семафор (partition-0 ... partition-255). Воркер, захвативший семафор, владеет партицией. Если воркер упал — семафор автоматически освобождается (эфемерность).
Дополнительно shared-семафор worker-registry отслеживает количество активных воркеров.
// Регистрация в реестре воркеров
registryLease, _ := session.AcquireSemaphore(ctx,
"worker-registry",
coordination.Shared,
options.WithEphemeral(true),
options.WithAcquireData([]byte(workerID)),
)
// Захват партиции
lease, _ := session.AcquireSemaphore(ctx,
fmt.Sprintf("partition-%d", partitionID),
coordination.Exclusive,
options.WithEphemeral(true),
)
Ребалансировка
Каждый воркер вычисляет свою целевую ёмкость: ceil(256 / количество_активных_воркеров) и захватывает партиции до этого лимита.
При изменении состава (отслеживается через DescribeSemaphore на worker-registry):
- Новый воркер подключился — все воркеры пересчитывают ёмкость вниз и освобождают лишние партиции
- Воркер отключился — ёмкость пересчитывается вверх, оставшиеся воркеры подбирают свободные партиции
Код ребалансировки:
func (r *Rebalancer) releaseExcess(newTarget int64) {
r.mu.Lock()
defer r.mu.Unlock()
excess := int64(len(r.leases)) - newTarget
released := int64(0)
for partitionID, lease := range r.leases {
if released >= excess {
break
}
lease.Release()
delete(r.leases, partitionID)
r.partitionCh <- partitionEvent{partitionID: partitionID, lease: nil}
released++
}
}
Жизненный цикл задачи
Вся работа с таблицей coordinated_tasks спрятана за интерфейсом TaskRepository (pkg/taskworker/repository.go) с тремя методами: FetchEligibleCandidate, ClaimTask, MarkCompleted. Захват задачи разбит на две фазы — это сознательное решение, которое снижает число конфликтов между воркерами.
Фаза 1 — FetchEligibleCandidate. Дешёвый snapshot read, выбирающий самую приоритетную подходящую задачу. Без serializable-транзакции, без блокировок:
// query.WithTxControl(query.SnapshotReadOnlyTxControl())
SELECT id, priority, payload
FROM coordinated_tasks
WHERE partition_id = $partition_id
AND (
status = 'pending'
OR (status = 'locked' AND locked_until < CurrentUtcTimestamp())
)
AND (scheduled_at IS NULL OR scheduled_at <= CurrentUtcTimestamp())
ORDER BY priority DESC
LIMIT 1
Условия выборки:
status = 'pending'— новая задачаstatus = 'locked' AND locked_until < now()— протухшая блокировка (воркер упал)scheduled_at IS NULL OR scheduled_at <= now()— время запуска наступило
Фаза 2 — ClaimTask. Узкая serializable-транзакция: сначала точечный SELECT по полному ключу (partition_id, priority, id) — подтверждаем, что задачу всё ещё можно захватить и её не забрал другой воркер между фазами. Затем выполняется conditional UPDATE с lock_value и locked_until:
return r.db.Query().DoTx(ctx, func(ctx context.Context, tx query.TxActor) error {
// 1) Подтверждаем, что задача ещё свободна
rs, _ := tx.Query(ctx, `
SELECT status, locked_until
FROM coordinated_tasks
WHERE partition_id = $partition_id AND priority = $priority AND id = $id`,
/* params: partition_id, priority, id */)
// ... scan status, locked_until ...
claimable := status == "pending" ||
(status == "locked" && currentLockedUntil != nil &&
currentLockedUntil.Before(time.Now().UTC()))
if !claimable {
return nil // тихо выходим, воркер возьмётся за следующего кандидата
}
// 2) Захватываем — точечный UPDATE по PK
return tx.Exec(ctx, `
UPDATE coordinated_tasks
SET status = 'locked',
lock_value = $lock_value,
locked_until = $locked_until
WHERE partition_id = $partition_id AND priority = $priority AND id = $id`,
/* params */)
}, query.WithTxSettings(query.TxSettings(query.WithSerializableReadWrite())))
Почему две фазы, а не одна? Идея простая: дорогой выбор кандидата остаётся вне serializable-транзакции, а строгие гарантии применяются только в момент захвата конкретной строки.
Snapshot-чтение с ORDER BY priority DESC LIMIT 1 свободно от конфликтов: оно не блокирует страницы и не вступает в серилизуемый порядок с другими транзакциями. Serializable-фаза работает уже только с одной строкой по полному PK — это самое узкое окно, где действительно нужны транзакционные гарантии.
Если объединить «выбор + захват» в одной serializable-транзакции, на горячих партициях с общими страницами будет больше TLI и ретраев.
Завершение — MarkCompleted — отдельная serializable-транзакция, UPDATE на status = 'completed' и done_at.
Backoff — если в партиции нет задач, воркер увеличивает интервал опроса экспоненциально (50ms → 100ms → 200ms → ... → 5s). При появлении задачи — сброс к минимуму.
Обработка сбоев
Три уровня отказоустойчивости:
-
Воркер упал — эфемерные семафоры освобождаются, другие воркеры подбирают партиции. Заблокированные задачи с истёкшим
locked_untilснова становятся доступными. -
Coordination session потеряна — ребалансер обнаруживает
session.Context().Done(), переоткрывает сессию, перерегистрируется и перезапускает захват партиций. -
Задача зависла —
locked_untilгарантирует, что через N секунд (по умолчанию 5) другой воркер перехватит задачу.
Когда использовать
- Нужны приоритеты и отложенный запуск
- Критична надёжность: ни одна задача не должна потеряться
- Система масштабируется горизонтально — воркеров может быть от 1 до десятков
- Нужен полный контроль над состоянием каждой задачи
Ограничения
- Высокая сложность реализации и эксплуатации
- Внутри партиций по-прежнему polling (нет push-уведомлений о новых задачах)
- Число логических партиций фиксировано (256) — изменение требует миграции.
- Нет встроенного DLQ — нужно реализовывать отдельно
Результаты теста
Для мониторинга оба приложения отдают Prometheus-метрики на :9090/metrics: target и observed rate, размер batch
и Backpressure у продюсера, число активных партиций, locked/processed/errors и статусы ответов API Gateway у воркера.
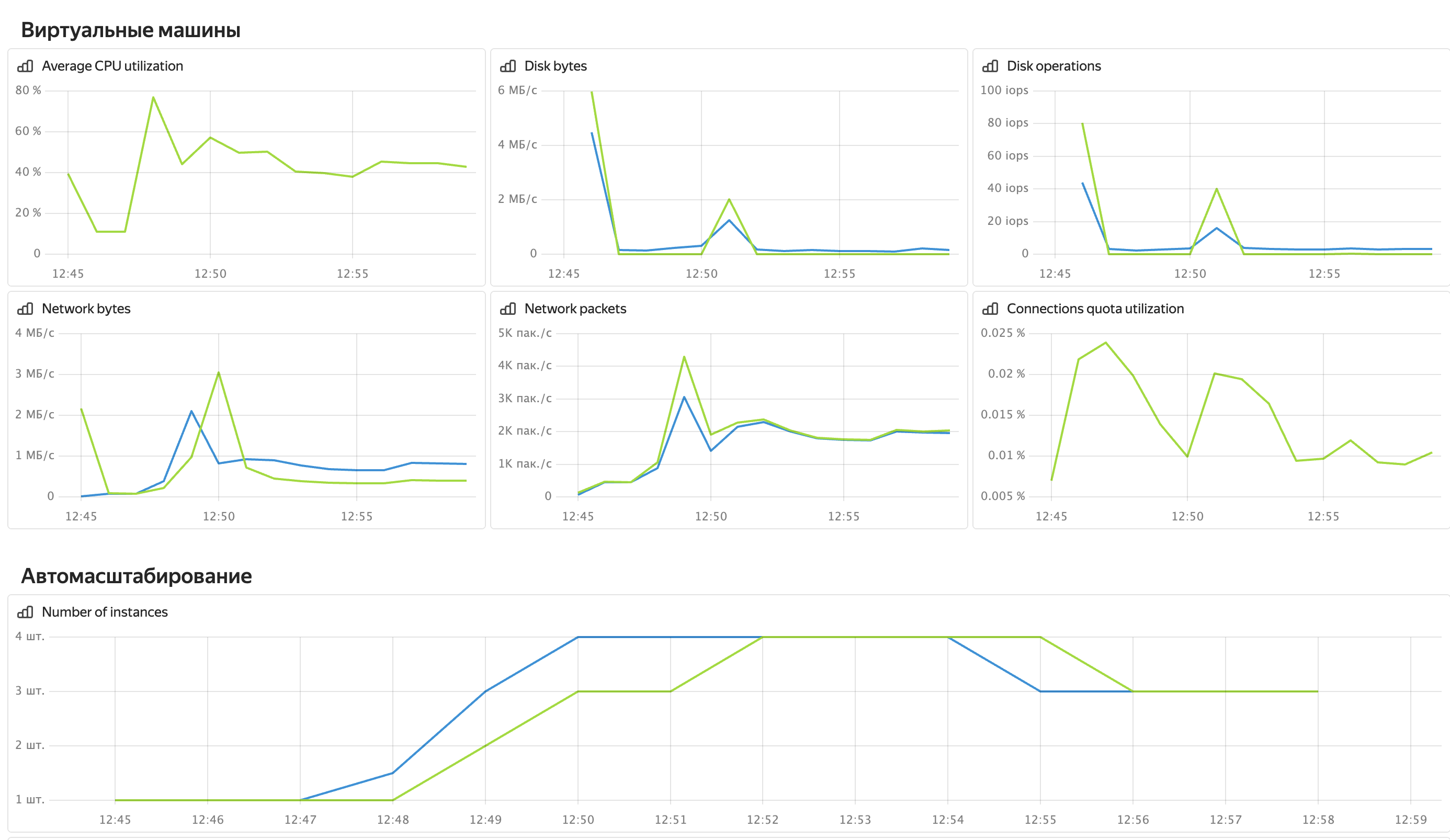
Видно, что в начале теста средняя загрузка процессора на единственном воркере достигает 80%, что запускает автомасштабирование Instance Group, для которой задано правило масштабирования CPU > 70%. Когда появляется второй воркер, нагрузка распределяется между ними. В пике развертывается 4 воркера, однако позже IG решает, что трех достаточно для поддержания целевого уровня загрузки.
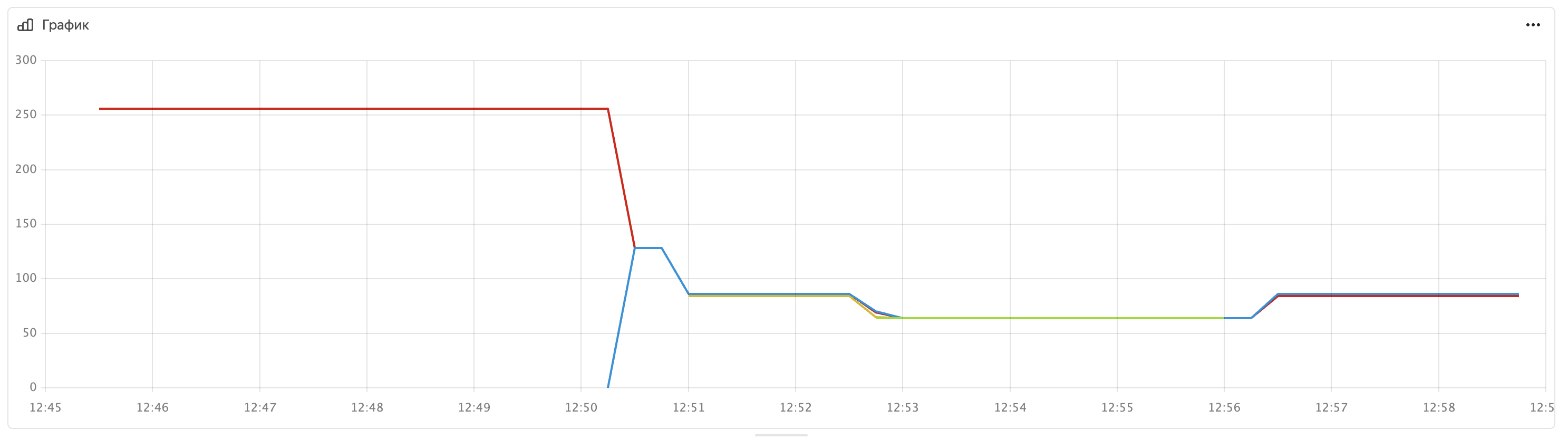
На этом графике отображется сколько партиций обрабатывает каждый воркер. В начале все 256 партиций обрабатывает единственный воркер. Когда появляется второй воркер, происходит ребалансировка: воркер 1 отдает часть партиций воркеру 2. (Красный график падает, синий растет). Далее тоже можно заметить ребалансировку при автоматическом масштабировании instance group.
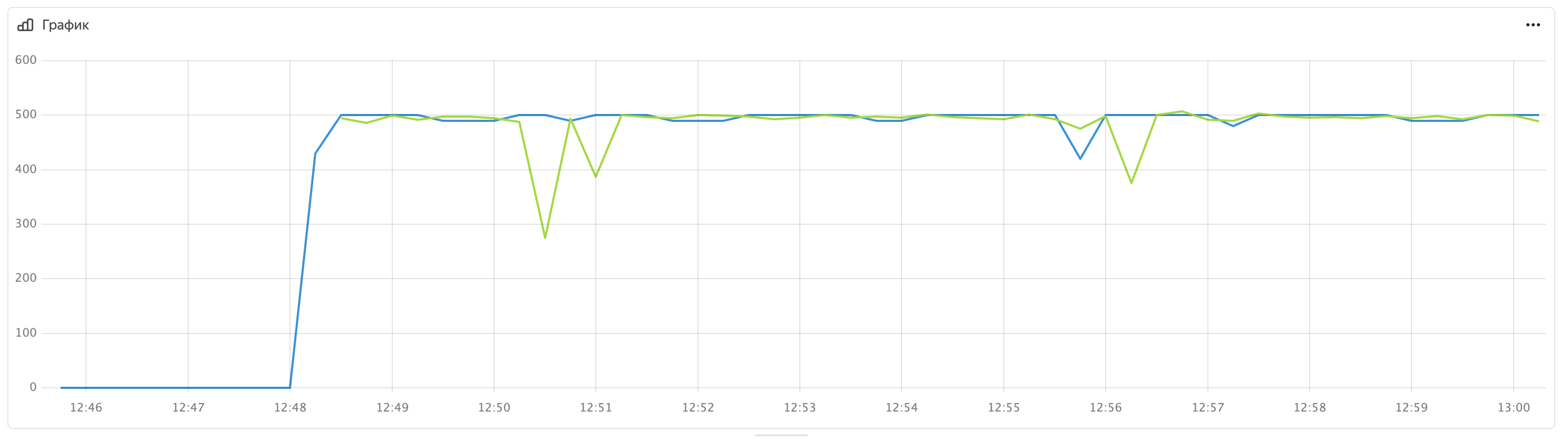
На этом графике синим показано скорость создания задач продюсером, зеленым — скорость обработки воркерами. Видно, что воркеры справляются с нагрузкой, поддерживая скорость обработки на уровне 500 задач в секунду. Небольшой разрыв между ними объясняется моментами ребалансировки.

И на финальном графике можно наблюдать данные с API Gateway, куда воркеры отправляют HTTP-запросы. Видно, что он так же регистрирует 500 запросов в секунду. Все ответы успешные, так как график ошибок пуст. Так же видно распределение по персентилям времен ответов.
Сравнение подходов
| Таблица | CDC | Topic API | Координация | |
|---|---|---|---|---|
| Модель доставки | Pull (polling) | Push (changefeed) | Push (topic) | Pull (per partition) |
| Контроль партицирования | Нет | Нет | Да | Да |
| Приоритеты | Нет | Нет | Нет | Да |
| Отложенный запуск | Нет | Нет | Нет | Да |
| Гарантии | Зависит от реализации | At-least-once | At-least-once | At-least-once |
| Ребалансировка | Нет | Consumer groups | Consumer groups | Coordination API |
| TLI-устойчивость | Зависит от паттерна | Зависит от паттерна | Контролируется ключом | Изоляция по партициям |
| Сложность | Минимальная | Низкая | Средняя | Высокая |
| YDB-примитивы | Query API | Query + CDC + Topic | Topic Writer/Reader | Query + Coordination |
Как выбрать
Три практических ориентира:
- Уже пишете в таблицу? Добавьте changefeed — и у вас подход 2 без единого изменения в продюсере.
- Нужен высокий throughput с минимумом конфликтов транзакций? Topic API с правильным ключом партицирования (подход 3).
- Нужна полноценная очередь задач? Инвестируйте в координированных воркеров (подход 4).
Заключение
YDB предоставляет все примитивы для построения системы обработки отложенных задач — от простого UPSERT в таблицу до распределённых координационных семафоров. Во многих сценариях отдельный брокер не нужен: таблицы, changefeed, топики и coordination nodes уже дают нужные строительные блоки в единой экосистеме с транзакционными гарантиями.
Главный практический вывод: начинайте с простого. Таблица + CDC покрывает большинство сценариев. Контроль партицирования через Topic API — следующий шаг, когда конкуренция за горячие ключи становится проблемой. Координированные воркеры — для случаев, когда нужна полноценная очередь с приоритетами и гарантиями.
Ещё один важный вывод: выравнивание ключа партицирования с паттерном доступа к данным часто оказывается самой эффективной оптимизацией. Бенчмарк из подхода 3 наглядно показывает: при правильном ключе TLI падает практически до нуля.
Весь код из статьи доступен в репозитории — каждый пример можно запустить локально с YDB в Docker.