Работа с Redis из Serverless-функций


Redis — это одна из самых популярных баз данных, используемая для кэширования и хранения данных. В этой статье мы рассмотрим, как работать с Redis из Serverless-функций в Yandex Cloud.
А именно, попробуем замерить время доступа к Redis из Serverless-функций и сравним его в разных условиях.
Проблема
В Serverless-функциях время доступа к базе данных может быть критично. Ведь функция запускается каждый раз заново и время доступа к базе данных может сильно влиять на время выполнения функции. Однако, вы не можете управлять зоной, где будет запущена ваша функция. Поэтому время доступа к базе данных может сильно варьироваться, если база данных находится в другой зоне.

Чтобы понять, как это влияет на время доступа к Redis, мы проведем эксперимент. Мы развернем Redis кластер из одной ноды и замерим время доступа к нему из Serverless-функций. Эти значения мы возьмем за базовый уровень, с которым будем сравнивать другие варианты.
Кластер на одну зону доступности
Для замера времени доступа к Redis мы будем использовать Serverless-функции в Yandex Cloud. Мы развернем Redis кластер из одной ноды и замерим время доступа к нему из Serverless-функций.
Код Serverless-функции:
package main
import (
"context"
"fmt"
"math/rand"
"os"
"strings"
"github.com/redis/go-redis/v9"
)
type Req struct {
Cmd string `json:"cmd"`
}
//goland:noinspection ALL
func Handler(ctx context.Context, req Req) ([]byte, error) {
addrs := strings.Split(os.Getenv("REDIS_ADDRS"), ",")
password := os.Getenv("REDIS_PASSWORD")
master := os.Getenv("REDIS_MASTER")
for i, addr := range addrs {
addrs[i] = strings.TrimSpace(addr) + ":26379"
}
conn := redis.NewUniversalClient(
&redis.UniversalOptions{
Addrs: addrs,
MasterName: master,
Password: password,
ReadOnly: req.Cmd != "seed",
},
)
if req.Cmd == "seed" {
seedData(ctx, conn)
return []byte("seeded"), nil
}
randKey := fmt.Sprintf("key%d", rand.Intn(1000))
result, err := conn.Get(ctx, randKey).Result()
if err != nil {
panic(err)
}
fmt.Println(result)
_ = conn.Close()
return []byte(result), nil
}
func seedData(ctx context.Context, conn redis.UniversalClient) {
for i := 0; i < 1000; i++ {
err := conn.Set(ctx, fmt.Sprintf("key%d", i), rand.Int(), 0).Err()
if err != nil {
panic(err)
}
}
}
Чтобы заполнить Redis данными, вызовите функцию с параметром {"cmd": "seed"}. Это создаст 1000 ключей со случайными значениями.
Результаты
Линии на графике показывают среднее время доступа к Redis из Serverless-функций.

sentinel-naive — это значения времени доступа к Redis из Serverless-функций, для кода приведенного выше.
direct-1 — это вариант, когда для доступа к кластеру вместо Sentinel по порту 26379 используется нода кластера по порту 6379.
Из графика видно, что при высокой нагрузке выбранный кластер из одно h2.nano ноды не справляется подключениями через Sentinel.
Особенно хорошо это видно на графике с кодами ошибок.

Кластер на три зоны доступности
Как видно из диаграммы выше, если у нас Redis только в одной зоне доступности, то вероятность получить ответ быстро,
будет равна 1/3 — когда функция и Redis находятся в одной зоне доступности.
Если же Redis будет в трех зонах доступности, то может показаться, что вероятность получить ответ быстро не изменится. Она также будет равна 1/3. Ведь условием быстрого ответа точно также будет нахождение функции и Redis в одной зоне доступности. (Тёмные стрелки на диаграмме. 3 варианта из 9.)

Может возникнуть закономерный вопрос: а зачем тогда разворачивать Redis в нескольких зонах доступности?
Причин несколько:
- Отказоустойчивость. Если Redis в одной зоне доступности упадет, то функции, которые находятся в других зонах доступности, смогут продолжать работу.
- Автоматический выбор мастера. Если мастер Redis упадет, то Sentinel автоматически выберет нового мастера.
- Уменьшение времени доступа. Для этого правда нам придется воспользоваться одной хитростью.
Хитрость
Вместо того чтобы использовать Sentinel для доступа к Redis, мы можем использовать ноду кластера напрямую. Это позволит нам уменьшить время доступа к Redis.
Остается вопрос, как нам выбрать правильную ноду кластера. Ведь изнутри Serverless-функций мы не можем узнать, в какой зоне доступности находится инстанс функции, который сейчас обрабатывает запрос.
Собственно хитрость и заключается в том, что нам не нужно знать ноду, мы можем отправить запросы одновременно на все ноды кластера. И выбрать ту, которая быстрее всего ответит.
Примерно так:
{
"NodeResponses": [
{
"Resp": "4793640638213908857",
"Dur": "1.419798ms",
"Addr": "rc1d-cqbed4er52dgo2dj.mdb.yandexcloud.net:6379"
},
{
"Resp": "4793640638213908857",
"Dur": "21.205729ms",
"Addr": "rc1a-nfjm2heo2r6isfcj.mdb.yandexcloud.net:6379"
},
{
"Resp": "4793640638213908857",
"Dur": "24.932153ms",
"Addr": "rc1b-6ie94pcd5q2jl7j9.mdb.yandexcloud.net:6379"
}
],
"Total": "25.392782ms"
}
Времена ответов от одиночных нод кластера — это только время вызова Redis-команды GET. Total — это полное время
работы функции, измеренное внутри нее.
Мы получили одинаковый ответ от всех нод кластера, но время ответа разное. Мы можем выбрать ноду с наименьшим временем ответа.
Вот код Serverless-функции, который это делает:
package main
import (
"context"
"encoding/json"
"fmt"
"math/rand"
"os"
"strings"
"time"
"github.com/redis/go-redis/v9"
)
type Duration struct {
time.Duration
}
func (d Duration) MarshalJSON() (b []byte, err error) {
return []byte(fmt.Sprintf(`"%s"`, d.String())), nil
}
type RespWithDur struct {
Resp string
Dur Duration
Addr string
}
type Response struct {
NodeResponses []RespWithDur
Total Duration
}
//goland:noinspection ALL
func Handler(ctx context.Context) ([]byte, error) {
funcStart := time.Now()
addrs := strings.Split(os.Getenv("REDIS_ADDRS"), ",")
password := os.Getenv("REDIS_PASSWORD")
randKey := fmt.Sprintf("key%d", rand.Intn(1000))
for i, addr := range addrs {
addrs[i] = strings.TrimSpace(addr) + ":6379"
}
responseChan := make(chan RespWithDur, 3)
doneChan := make(chan struct{})
cCtx, cancel := context.WithCancel(ctx)
for _, addr := range addrs {
go func(addr string) {
start := time.Now()
conn := redis.NewUniversalClient(
&redis.UniversalOptions{
Addrs: []string{addr},
Username: "default",
Password: password,
ReadOnly: true,
},
)
defer conn.Close()
result, err := conn.Get(cCtx, randKey).Result()
if err == nil {
responseChan <- RespWithDur{Resp: result, Dur: Duration{time.Since(start)}, Addr: addr}
doneChan <- struct{}{}
}
}(addr)
}
<-doneChan
cancel()
close(responseChan)
close(doneChan)
var res []RespWithDur
for resp := range responseChan {
res = append(res, resp)
}
response := Response{
NodeResponses: res,
Total: Duration{time.Since(funcStart)},
}
return json.Marshal(response)
}
Результаты
Линии на графике:
sentinel-naive— это значения времени доступа к Redis из Serverless-функций, с использованием Sentinel с перечислением всех трёх нод кластера. Код который обычно приводится в примерах.direct-1— это вариант, когда для доступа к кластеру вместо Sentinel по порту26379используется нода кластера по порту6379. И выбирается нода с наименьшим временем ответа.direct-3— это вариант, аналогичныйdirect-1, но мы дожидаемся ответа от всех трёх нод кластера. Очевидно этот вариант всегда должен быть медленнееdirect-1.
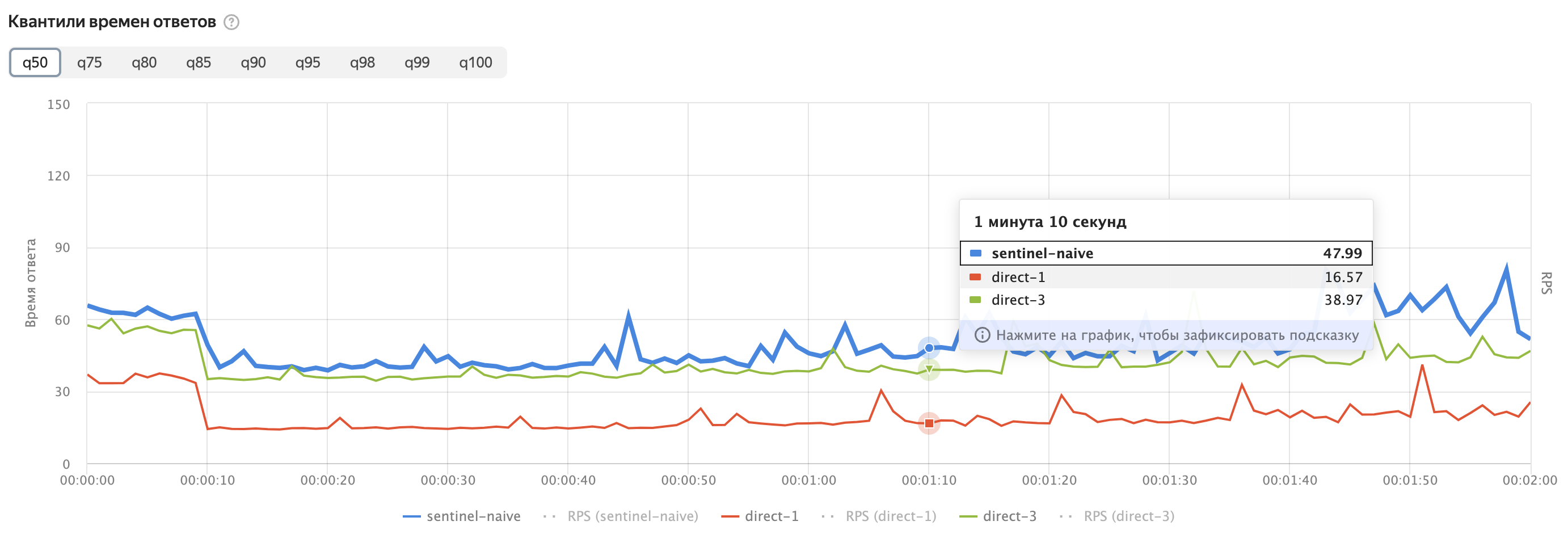
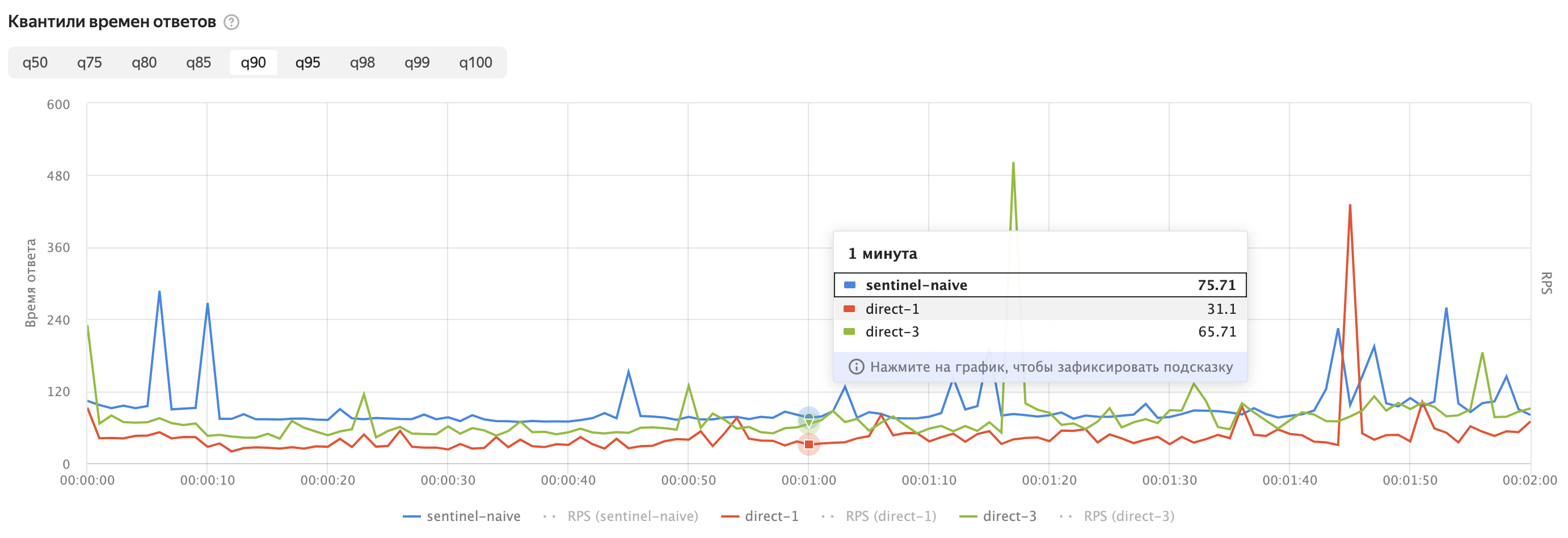
Из графиков видно, что использование нод кластера напрямую позволяет уменьшить время доступа к Redis из Serverless-функций. Время измеренное в этих тестах — это полный round-trip time вызова функции. Оно больше, чем чистое время доступа к Redis, но показывает те значения, которые важны для пользователей.
Возможные доработки
Если ваша функция вызывается часто, то можно кэшировать внутри инстанса адрес ноды кластера, которая быстрее всего отвечает. Это позволит сэкономить время на выборе ноды и снизит нагрузку на Redis, так как 3 запроса вместо одного мы будем отправлять только в первый раз.
Также можно кешировать соединение с Redis с самой быстрой нодой. Значительной разницы во времени между этими двумя подходами я не заметил.
Подробнее тут.