Serverless Full Text Search на Go


В прошлом Serverless Full Text Search я рассмотрел JavaScript библиотеку для in-memory полнотекстового поиска Lyra. Почему я выбрал именно ее? Во-первых, именно на доклад про неё я наткнулся на YouTube. Во-вторых, мне понравилась её универсальность и возможность притащить её в браузер.
Но при этом я могу выделить несколько минусов:
- In-memory. И хотя именно это и дает ей портабельность и скорость, но загрузку индекса в память на холодном старте уходит значительное время (~5сек) и с этим ничего не сделать.
- К тому же индекс в памяти занимает значительное место, то есть нам придется выделять функции больше памяти, а значит и платить за эти ресурсы.
- На текущий момент поддерживаются индексы только по строковым полям, другие типы, например, по числовым, по датам или GeoSpatial индексы не поддержаны.
- Нет фасетного поиска. Что это такое? Это когда при поиске найденные документы классифицируются по заданным свойствам — фасетам. Эта информация возвращается вместе результатами поиска и у вас есть возможность на фронте отрисовать дополнительные фильтры, чтобы пользователь мог легко уточнить свой запрос. (UPD 2023–01–27: В Lyra добавили фасеты.)
И поискав немного, я нашел новую библиотеку на этот раз на Go.
Bleve
Название не очень благозвучное, но оно происходит от акронима BLEVE — Boiling liquid expanding vapor explosion. Именно поэтому у библиотеки такое лого.

Она поддерживает
- Индексацию любых Go структур, включая JSON;
- Гибкую настройку, при этом имея значения по умолчания, которые позволят вам свести конфигурирование к минимуму;
- Индексы по: Text, Numeric, Datetime, Boolean;
- Разные типы запросов:
— Термин или фраза с точным или частичным совпадением, Fuzzy-поиск (неточное совпадение по расстоянию Левенштейна);
— Конъюнкция(«И»), дизъюнкция(«ИЛИ»), Булевы модификаторы (must в поисковом запросе
+перед термином, should — уровень по умолчанию и must_not —-перед термином); — Term Range, Numeric Range, Date Range; — Geo Spatial - Удобный для людей синтаксис запросов;
- tf-idf скоринг;
- Бустинг (Вы можете повлиять на относительную важность частей запроса, добавив к ним суффикс с помощью оператора
^, за которым следует число.); - Подсветку найденного в результатах;
- Поддержка агрегации фасетов: по терминам, числовым или временным диапазонам.
Эксперименты
Для того чтобы результаты можно было сравнивать с предыдущей статьёй я буду использовать тот же датасет анекдотов на русском языке на 124к документов.
Построение индекса
Строить индекс можно и программно, но кроме этого bleve предоставляет одноименную консольную утилиту, которая позволит вам работать с индексом.
Установка.
go install github.com/blevesearch/bleve/v2/cmd/bleve@latest
$ bleve --help
Bleve is a command-line tool to interact with a bleve index.
Usage:
bleve [command]
Available Commands:
bulk bulk loads from newline delimited JSON files
check checks the contents of the index
count counts the number documents in the index
create creates a new index
dictionary prints the term dictionary for the specified field in the index
dump dumps the contents of the index
fields lists the fields in this index
help Help about any command
index adds the files to the index
mapping prints the mapping used for this index
query queries the index
registry registry lists the bleve components compiled into this executable
scorch command-line tool to interact with a scorch index
Flags:
-h, --help help for bleve
Use "bleve [command] --help" for more information about a command.
Именно при помощи нее я подготовил индекс, загрузив в него документы в формате JSON per line. Но для начала нам нужно будет создать файл с описанием структуры индексируемых документов.
{
"types": {
"joke": {
"fields": [
{
"name": "joke",
"type": "text",
"analyzer": "ru",
"store": true,
"index": true
}
]
}
},
"type_field": "_type",
"default_type": "film"
}
Далее на основе него создать индекс.
bleve create -m data/mapping.json data/index
Далее индексируем датасет.
bleve bulk data/index data/dataset.jsonl
В директории data/index появится файл с метаданными индекса и директория store со следующим содержимым:
-rw------- 1 nikolay nikolay 40M Jan 7 21:46 000000000044.zap
-rw------- 1 nikolay nikolay 9.1M Jan 7 21:46 000000000050.zap
-rw------- 1 nikolay nikolay 9.1M Jan 7 21:46 000000000059.zap
-rw------- 1 nikolay nikolay 9.0M Jan 7 21:46 000000000064.zap
-rw------- 1 nikolay nikolay 8.6M Jan 7 21:46 00000000006e.zap
-rw------- 1 nikolay nikolay 8.8M Jan 7 21:46 000000000079.zap
-rw------- 1 nikolay nikolay 9.3M Jan 7 21:46 000000000083.zap
-rw------- 1 nikolay nikolay 1.2M Jan 7 21:46 000000000084.zap
-rw------- 1 nikolay nikolay 1.2M Jan 7 21:46 000000000085.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 000000000086.zap
-rw------- 1 nikolay nikolay 1.2M Jan 7 21:46 000000000087.zap
-rw------- 1 nikolay nikolay 1.2M Jan 7 21:46 000000000088.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 000000000089.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 00000000008a.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 00000000008b.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 00000000008c.zap
-rw------- 1 nikolay nikolay 1.3M Jan 7 21:46 00000000008d.zap
-rw------- 1 nikolay nikolay 1.2M Jan 7 21:46 00000000008f.zap
-rw------- 1 nikolay nikolay 236K Jan 7 21:46 000000000090.zap
-rw------- 1 nikolay nikolay 64K Jan 7 21:47 root.bolt
Общий размер файлов 109Mb, что меньше сериализованного в JSON индекса Lyra(130Mb). К сожалению этот индекс гораздо хуже жмется zip’ом — 59Mb против 33. Зато его не нужно будет грузить в память.
Изначально Bleve использовал индекс под названием «upsidedown», который в качестве хранилища использовал Key-Value хранилища BoltDB/RocksDB/LevelDB/Moss. Новый индекс «scorch» работает с диском напрмую. При создании вы можете выбрать тип индекса.
Тесты bleve индекса я проводил на функции со 128Mb, в то время как для Lyra требовалось минимум 1Gb. Вероятно, дело не только в размере памяти, но и в выделяемой доле CPU, которая пропорциональна памяти, потому что при 768Mb запрос к Lyra не укладывался в 15 секунд на «холодном» старте.
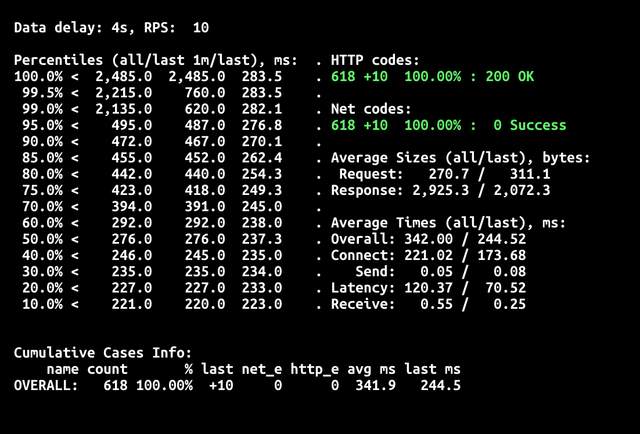
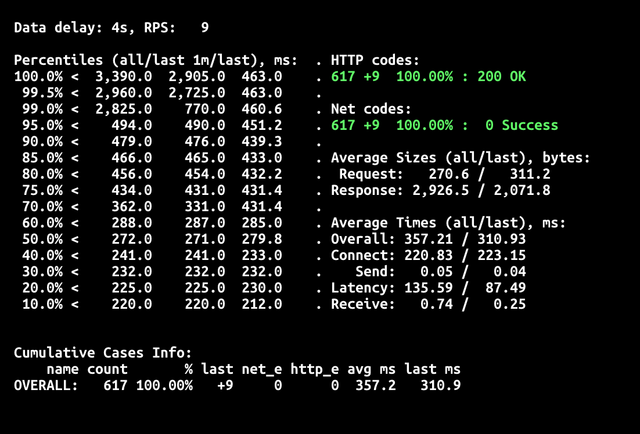
То есть bleve версия уже в 8 раз дешевле. Давайте сравним тайминги «холодного» старта.
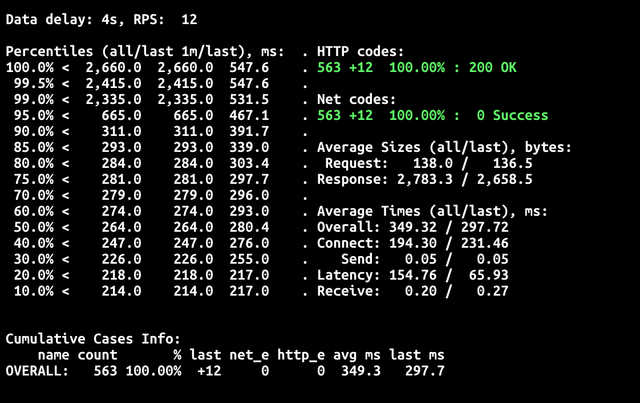
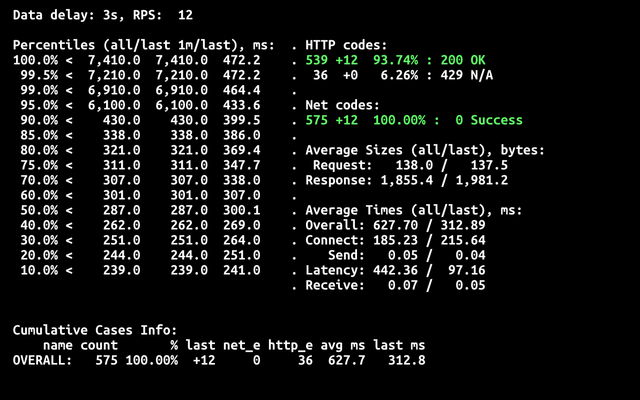
Что можно заметить? Во-первых, гораздо ниже время холодного старта ~2,5сек против ~7сек. Во-вторых, нет 429 кодов ошибок. Это тоже связано с меньшим временем старта: запросы не успевают переполнить очередь и превысить zone_requests_limit. В остальном значения на 90-персентиле сравнимы, а значит при кванте в 100мс вы будете оплачивать одинаковое время, с упомянутой выше поправкой на размер требуемой памяти.
В итоге экономия в зависимости от количества «холодных» стартов у вас будет от 8 до 23 раз.
Еще мне было интересно посмотреть куда в bleve уходит время.
{
...
"durations": {
"checkCache": 372,
"getObjectInfo": 35617,
"downloadAndUnzip": 2095123,
"openIndex": 18213,
"queryIndex": 2804,
"closeIndex": 238
}
}
Значения в микросекундах (10⁻⁶). Проверка наличия кэша, получение данных про индекс(необходимо знать размер для распаковки zip) скачивание и распаковка, открытие индекса, запрос и закрытие индекса.
Если индекс не закрыть, то на «горячем» старте функция повиснет в ожидании доступа к базе.
Фасеты и язык запросов
Подготовка данных и измерения
Так как на анекдотах строить фасеты не на чем, для этого эксперимента я взял датасет с сайта открытых данных министерства культуры. В нем 97k документов про выданные прокатные удостоверения.
Когда я пробовал построить индекс используя все поля у меня не хватало места в директории /tmp, хотя формально я не превышал указанные в документации 512mb. Но разбираться в чем там проблема мне не очень хотелось, поэтому я выкинул часть полей, получив индекс меньшего размера — 189Mb. Именно для него будут приведены следующие измерения.
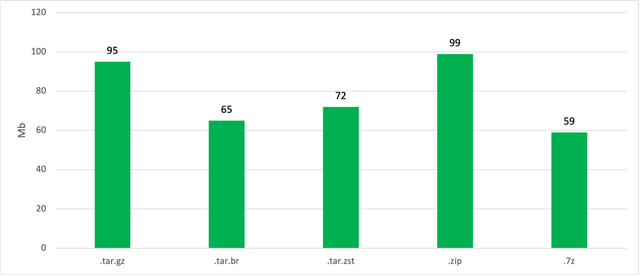
Отсюда видно, что 7z дает наилучшее сжатие в этом случае, но если посмотреть на время распаковки, то станет понятно, почему я бы не стал его рекомендовать для использования в serverless варианте.
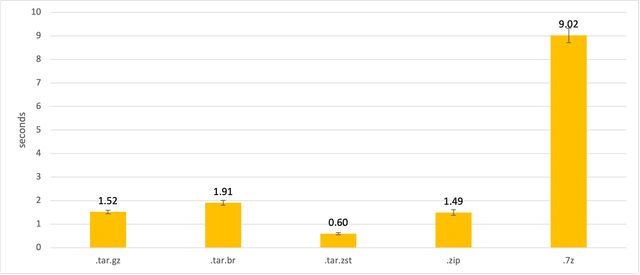
Как видно из графика 7z в разы медленнее остальных алгоритмов. Замеры времени распаковки проводились локально, в функции со 128Мб памяти время может быть больше.
Победитель тут Tar архив сжатый при помощи Zstd (степень сжатия 11). И если посмотреть на замеры скачивания архивов из S3 в функцию, то можем увидеть, что при потоковой распаковке этот вариант не должен вносить сильных дополнительных расходов.
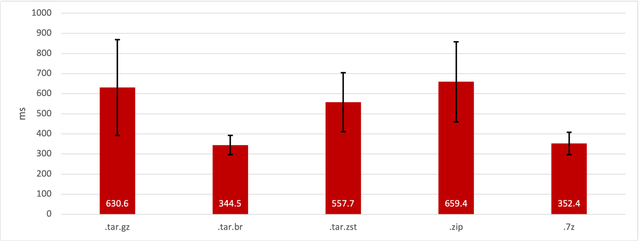
Из этого графика так же видно, что время скачивания архива для всех случаев сравнимо или даже меньше времени распаковки, так что даже сильный разброс значений не даст значимого влияния на общее время «холодного» старта.
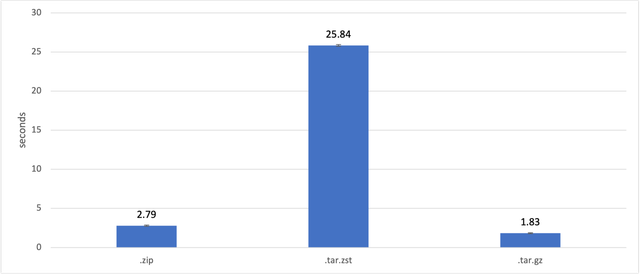
Стоит конечно упомянуть, что время создания .tar.zst архива на порядок больше чем .tar.gz. Но для статических индексов (количество поисков >>> количества обновлений), я считаю, это все равно оптимальный вариант.
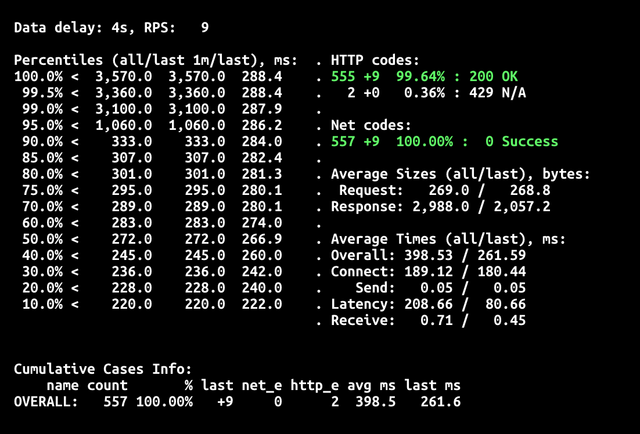
Увеличение ресурсов функции (128 → 1024Мб) не дало значительного снижения времени холодного старта. Разница составила не более 10%. Это меньшее влияние, чем выбор оптимального алгоритма сжатия.
Построение фасетов
Для того чтобы запрос вернул фасеты, вам нужно описать их в поисковом запросе.
searchRequest := bleve.NewSearchRequest(query)
// для построения фасета по годам мы добаляем числовые дипазоны
yearFacet := &bleve.FacetRequest{
Size: 20,
Field: "crYearOfProduction",
}
for i := 2000; i < 2020; i++ {
minY := float64(i)
maxY := float64(i + 1)
yearFacet.AddNumericRange(strconv.Itoa(i), &minY, &maxY)
}
searchRequest.Facets = bleve.FacetsRequest{
"year": yearFacet,
// фасет по странам будет содержать не более 5 наиболее популярных вариантов
"country": &bleve.FacetRequest{
Size: 5,
Field: "countryOfProduction",
},
}
В ответе сервера мы получим следующее.
{
...
"total_hits": 23,
"took": 24200091, // 24ms
"facets": {
"country": {
"field": "countryOfProduction",
"total": 25,
"missing": 0,
"other": 3,
"terms": [
{
"term": "россия",
"count": 11
},
{
"term": "индия",
"count": 5
},
{
"term": "канада",
"count": 3
},
{
"term": "великобритания",
"count": 2
},
{
"term": "австралия",
"count": 1
}
]
},
"year": {
"field": "crYearOfProduction",
"total": 23,
"missing": 0,
"other": 0,
"numeric_ranges": [
{
"name": "2004",
"min": 2004,
"max": 2005,
"count": 23
}
]
}
}
}
Внимательный читатель обратит внимание, что total в фасетах различается. Всего поиск вернул 23 результата, а для стран количество 25. Это потому что у двух документов в этом поле указано 2 страны.
Вообще хотел бы отметить, что хоть документация для этой библиотеки и существует, но вы довольно быстро перейдете к чтению исходных кодов. Если вас это не пугает, то bleve очень мощный и относительно простой инструмент.
Как обычно ссылка не репозиторий с кодом.