Автоинкремент в Yandex Database


Его нет. И вообще это плохая идея и вот почему.
tl;dr:
Используйте UUID в качестве первичных ключей. Их можно публиковать без раскрытия конфиденциальной информации, их нельзя угадать и они эффективны.
Первичные, технические и семантические ключи
Реляционная база данных — это граф, узлы которого называются сущностями, а ребра — отношениями. Чтобы иметь возможность выразить отношение между сущностями, мы должны иметь возможность однозначно ссылаться на любую сущность: это роль первичного ключа.
Роль первичного ключа заключается в обеспечении стабильной, индексируемой ссылки на объект. У вас есть два способа построить свой первичный ключ: либо как семантический ключ, либо как технический ключ.
Семантический первичный ключ извлекается из атрибутов сущностей (то есть вы используете одно или несколько полей вашей сущности в качестве ее первичного ключа).
Технический первичный ключ совершенно не связан с полями его сущности. Он создается, когда сущность вставляется в БД.
В идеале семантические ключи были бы лучше, так как они дают очень простой способ понять и сравнить сущности. Но реляционные БД построены на фундаментально изменчивой модели. Текущее состояние мира хранится в базе данных, а сущности подвержены мутациям. Реляционные БД очень хорошохранят относительно небольшой объем данных и плохо подходят для неизменяемых баз данных.
Вот почему для того, чтобы иметь стабильные первичные ключи, мы обычно прибегаем к серийным идентификаторам (Serial, AUTO_INCREMENT). Серийные идентификаторы являются техническим ключом, поскольку они не связаны с фактическим содержимым его сущности.
Какие проблемы могут вызвать серийные идентификаторы
- Раскрытие информации Текущее значение соответствует последнему значению, используемому в качестве первичного ключа. Поскольку последовательность начинается с 1 и увеличивается 1 за раз. В итоге примерно соответствует количеству строк в таблице (не совсем, из-за удалений). Получается, если вы хотите подсчитать количество строк в данной таблице, все, что вам нужно сделать, это заставить систему сгенерировать новую сущность и проверить ее идентификатор. Есть ли у пользователей доступ к первичным ключам? Ответ часто бывает утвердительным: первичные ключи очень часто доступны пользователю, чаще всего в URL-адресах, поскольку мы хотим, чтобы URL-адреса были стабильными (см. Cool URIs don’t change) Допустим, вы являетесь компанией, работающей с SaaS, и все, что нужно знать о вашем количестве пользователей, — это создать учетную запись.
- Перебор объектов Еще большая проблема заключается в том, что очень легко перебрать все сущности в любой таблице. Вы начинаете с 1 и продолжаете увеличивать значение. Вытащить все ваши данные становится очень легко. Это приводит к спаму (только не начинайте с 1, так как вы не хотите спамить администраторскую команду ;-) ), или еще хуже. Если у вас есть легкий контроль доступа, основанный только на знании данного URL-адреса, то любой может увидеть личную информацию.
- Отсутствие уникальности между таблицами Поскольку каждая таблица имеет свою собственную последовательность, одно и то же значение может встречаться как ключ в разных таблицах. Теперь представьте, что при написании delete-запроса вы делаете опечатку в названии таблицы, нажимаете
Tabдля автодополнения,Enter. Поздравляю, вы только что удалили произвольную строку где-то в своей БД. - Производительность Автоинкремент будет узким местом, если вам придется обрабатывать большое количество вставок. А именно для такой модели проектировалась YDB.
Вы конечно можете настроить последовательность, чтобы она начиналась не с 1 или использовать произвольный шаг. Но это все рано не спасет вас от описанных выше проблем.
UUID
Universally Unique IDentifier, например такой 8E976A90-EC41–40E4–975A-46CE40162591.
UUID гарантированно являются универсально уникальными, что делает их хорошими кандидатами на первичные ключи (и аккуратно решает проблему первичных ключей, не являющихся уникальными в разных таблицах).
Точнее, UUID-это 128-битные значения с текстовым представлением в шестнадцатеричных цифрах.
К сожалению тип данных
UUIDне поддерживается в YDB в качестве типа колонки, поэтому придется хранить его в виде текста (StringилиUtf8).
Существует несколько версий алгоритмов генерации UUID.
- Version 1 — на основе даты, времени и MAC-адреса
- Version 2 — на основе даты, времени, MAC-адреса и DCE
- Versions 3 и 5 — на основе неймспейса
- Versions 4 — случайные
UUIDv4
Поскольку значения UUIDv4 случайны, у вас нет гарантированной уникальности. Однако вероятность столкновения довольно мала (см. Случайную UUID-вероятность дубликатов).
Кроме того, имейте в виду, что в крайне маловероятном случае (вы с большей вероятностью попадете под метеорит) коллизии UUID он будет пойман БД благодаря ограничению первичного ключа.
Коллизия возникает, когда один и тот же UUID генерируется более одного раза и назначается разным сущностям. В UUIDv4, коллизии могут возникать даже без проблем реализации, хотя и с такой малой вероятностью, что ее обычно можно игнорировать. Эта вероятность может быть точно вычислена на основе анализа парадокса дней рождений.
Например, число случайных UUIDv4, которые должны быть сгенерированы для того, чтобы иметь 50%-ную вероятность хотя бы одной коллизии, составляет 2,71 квинтиллиона, вычисленное следующим образом:
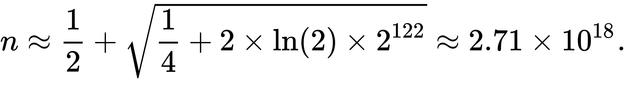
Это число эквивалентно генерации 1 миллиарда UUID в секунду в течение примерно 85 лет. Файл, содержащий такое количество UUID, по 16 байт на UUID, будет составлять около 45 экзабайт.
В UUIDv4 свободных 122 бита информации, остальные зарезервированы для указания версии идентификатора.
2 ^ 122 = 5316911983139663491615228241121378304
Кажется этого должно быть достаточно для ваших нужд.
Тот факт, что значения UUIDv4 случайны, дает нам интересные свойства:
- данные не подвержены перебору
- внешний наблюдатель не сможет сказать сколько значений присутствует в каждой таблице
- не нужно ходить в БД, чтобы сконструировать новый объект
Два первых свойства хороши, прокрутите вверх, если вы не помните, почему. Третье заслуживает некоторых дополнительных объяснений.
Источником знаний про значение автоинкремента служит база. Каждый раз, когда вам нужно вставить объект, вам нужно, чтобы БД дала вам свой первичный ключ. Сущности в вашем коде являются неполными, пока вы не сходите в БД. При вставке нескольких связанных сущностей это может вызвать дополнительные проблемы, поскольку вам не хватает не только первичных ключей, но и внешних ключей, которые являются семантическими, а не только техническими.
Как сгенерить UUID на вашем любимом языке
Java, Scala
Есть в стандартной библиотеке.
java.util.UUID.randomUUID
Python
Есть в стандартной библиотеке.
import uuid
uuid.uuid4()
Node.js
npm install uuid
var uuid = require("uuid");uuid.v4();
PHP
Ставим ramsey/uuid через composer.
$uuid4 = Uuid::uuid4();
UUIDv1
Если же вы все равно хотите упорядоченные по времени значения, то можете посмотреть в сторону UUIDv1.
Пример на Python3.
import uuid
ids = [uuid.uuid1() for i in range(5)]
assert list(sorted(ids)) == ids
Можно убедиться, что значения идут по порядку.
169e11b0-78f4-11eb-a7e2-acde48001122
16a1b614-78f4-11eb-a88e-acde48001122
16a1b7e8-78f4-11eb-9f61-acde48001122
16a1b846-78f4-11eb-bef0-acde48001122
16a1b88a-78f4-11eb-aa7a-acde48001122