Как озвучить книгу при помощи SpeechKit API Yandex.Cloud

Скрипт для озвучивания длинного текста.
Для того начала нам нужно будет зарегистрироваться в Yandex Cloud и создать платежный аккаунт.
Дальше нужно получить API ключ, при помощи которого мы будем авторизовывать наши запросы.
Как получить API-ключ
Откройте https://console.cloud.yandex.ru/cloud
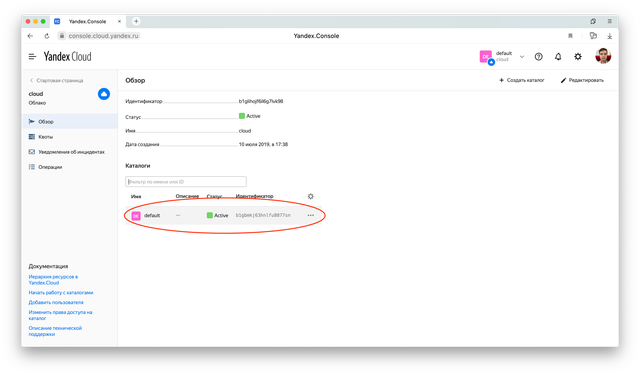
Кликните на фолдер
Далее в левом меню перейдите на вкладку Сервисные аккаунты.
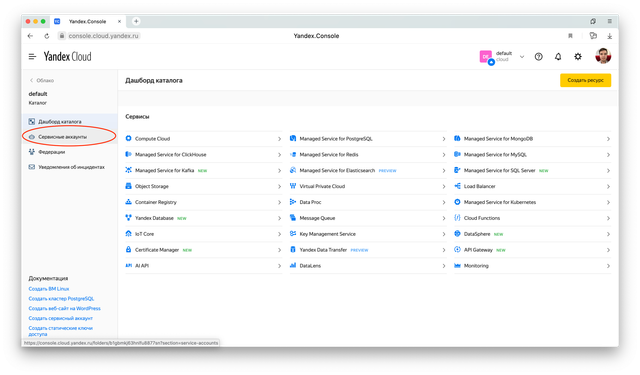
Нам потребуется создать один. У меня уже он есть, но вот подробная инструкция как создать еще один:
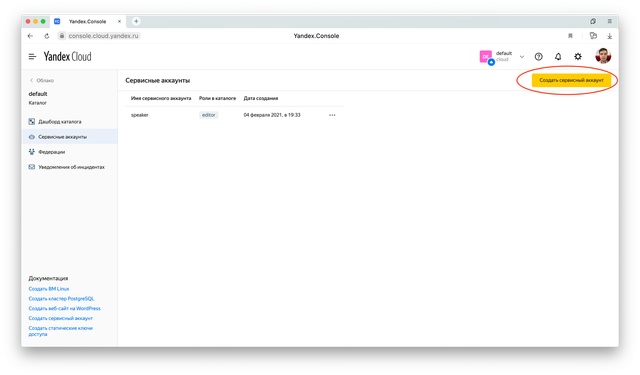
Кликните на кнопку «Создать сервисный аккаунт»
Задайте ему имя и добавьте роль editor.
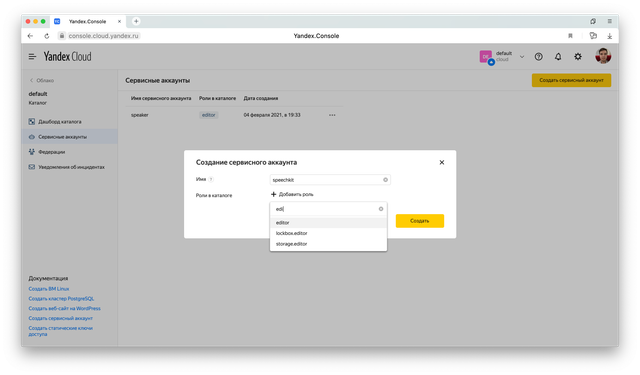
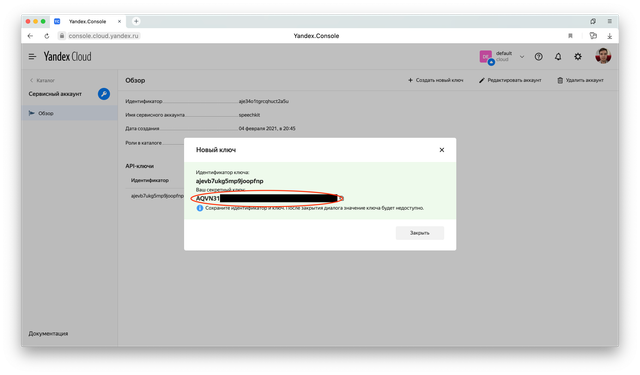
После этого кликните в только что созданный аккаунт и создайте новый API-ключ.
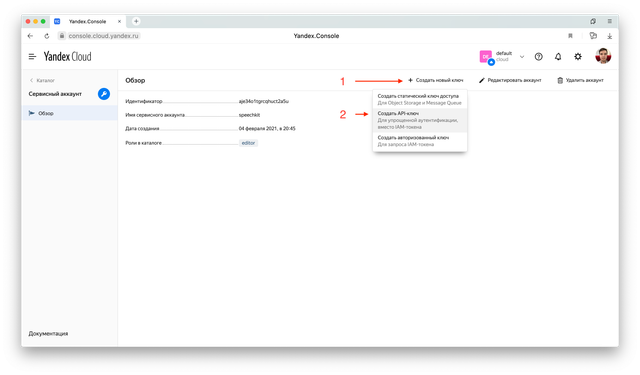
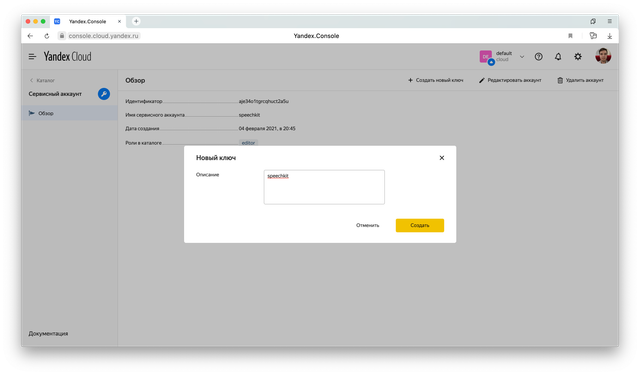
Ключу можно добавить описание, чтобы не путаться потом между разными ключами.
Скопируйте API-ключ в какой-нибудь файл. Потому что больше его увидеть нельзя будет. Можно будет только создать новый.
Пример на Python
Код на Python 3.8 для озвучивания текста. Для примера я взял текст А.С. Пушкина из Повестей Белкина, потому что он уже в public domain и на него не распространяются авторские права. Текст я сохранил в кодировке utf-8 и немного почистил от сносок. Так же оставил только русские переводы французских фраз, так как SpeechKit не поддерживает французский язык.
Я заметил, что несмотря на то, что поддерживается синтез звука по отрывкам текста длинной до 5000 тыс. знаков, лучше работает с небольшими кусками. Поэтому я поделил текст на отдельные предложения и озвучивал их.
У SpeechKit есть мужские и женские голоса и теоретически, женские реплики можно было бы озвучить отдельно другим голосом, но для этого пришлось бы дополнительно разметить текст, а я хотел сделать максимально простой пример.
Размер выбранного произведения — 22 тыс. знаков. Озвучивание его при помощи премиального голоса Филипп обошлось в 27₽.
import os
import requests
API_KEY = os.environ["API_KEY"]
def format_filename(i: int) -> str:
return f"{i:05d}.ogg"
def make_req(text, n: int):
# Сформируем заголовок запроса с ключем авторизации
headers = {
"Authorization": f"Api-Key {API_KEY}"
}
# Отправим запрос
res = requests.post(
"https://tts.api.cloud.yandex.net/speech/v1/tts:synthesize",
{
"text": text,
"lang": "ru-RU",
"voice": "filipp",
"emotion": "neutral"
},
headers=headers)
# И запишем результат в файл
filename = format_filename(n)
with open(f"out/{filename}", "wb") as out:
out.write(res.content)
def main(f_name):
# Создадим директорию куда будем складывать результат
try:
os.mkdir("out")
except:
pass
with open(f_name) as f:
n = 1
while line := f.readline():
# Пропустим пустые строки
if line == '\n':
continue
# Делим строку на предожения
sentences = line.split('.')
for sentence in sentences:
# Убираем лишние пробелы и переводы строк
sentence = sentence.strip(" \n")
# И опять, пустые предложения пропускаем
if not sentence:
continue
# Возвращаем на место точки
sentence = sentence + "."
# Печатаем предложени
print(n, sentence)
# Делаем запрос
make_req(sentence, n)
n = n + 1
# Собираем список созданных файлов
with open("out/list.txt", "w") as f:
for i in range(1, n + 1):
filename = format_filename(i)
line = f"file '{filename}'\n"
f.write(line)
# При помощи ffmpeg склеим все файлы в один
os.system("ffmpeg -f concat -i out/list.txt -c copy out/output.ogg")
if __name__ == '__main__':
main('book.txt')
Этот скрипт побьет текст на предложения, озвучит их в SpeechKit и потом склеит результат при помощи ffmpeg.
Как установить ffmpeg на ваш компьютер можно посмотреть тут.
Весь код примера на гитхаб.
Кстати если вам хочется получить вместо Ogg Opus файла обычный MP3, то сделать это можно при помощи того же ffmpeg.
Для этого нужно выполнить следующую команду
ffmpeg -i out/output.ogg -acodec libmp3lame out/output.mp3
После этого в терминале вы увидите примерно следующее:
ffmpeg version 4.3.1 Copyright (c) 2000-2020 the FFmpeg developers
built with Apple clang version 12.0.0 (clang-1200.0.32.28)
configuration: --prefix=/usr/local/Cellar/ffmpeg/4.3.1_9 --enable-shared --enable-pthreads --enable-version3 --enable-avresample --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libbluray --enable-libdav1d --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-librtmp --enable-libspeex --enable-libsoxr --enable-videotoolbox --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack
libavutil 56. 51.100 / 56. 51.100
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
libswresample 3. 7.100 / 3. 7.100
libpostproc 55. 7.100 / 55. 7.100
Input #0, ogg, from 'out/output.ogg':
Duration: 00:25:40.29, start: 0.006500, bitrate: 85 kb/s
Stream #0:0: Audio: opus, 48000 Hz, mono, fltp
Metadata:
encoder : Lavf57.56.100
Stream mapping:
Stream #0:0 -> #0:0 (opus (native) -> mp3 (libmp3lame))
Press [q] to stop, [?] for help
Output #0, mp3, to 'output.mp3':
Metadata:
TSSE : Lavf58.45.100
Stream #0:0: Audio: mp3 (libmp3lame), 48000 Hz, mono, fltp
Metadata:
encoder : Lavc58.91.100 libmp3lame
size= 12039kB time=00:25:40.29 bitrate= 64.0kbits/s speed=87.9x
video:0kB audio:12039kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.001922%
Как видно наш исходный поток opus, 48000 Hz, mono, 85 kb/s был пережат в mp3 с параметрами mp3 (libmp3lame), 48000 Hz, mono, fltp 64.0kbits/s .
Дьявол кроется в деталях, так что для получения действительно качественного продукта придется хорошо подготовить текст и вероятно внимательно отслушать результат. Удачных экспериментов.