Serverless Full Text Search


Если вы для своего проекта выбрали serverless стек, то наверняка вы заметили, что в Яндекс Облаке для него нет решения обеспечивающего полнотекстовый поиск. Ну, то есть вы конечно можете поднять кластер ElasticSearch. Но при его минимальной стоимости и выделяемых ресурсах это наверняка будет стрельбой из пушки по воробьям.
Но что же делать, если хочется сохранить низкие расходы на инфраструктуру и получить быстрый полнотекстовый поиск?
Построить индекс и работать с ним из функций. Для этого мы возьмем js библиотеку Lyra. Это библиотека in-memory полнотекстового поиска, которая работает как на клиенте, так и на сервере.
Upd: Авторы переименовали библиотеку в Orama
Благодаря использованию оптимизированного префиксного дереваи некоторым хакам Lyra может выполнять поиск по миллионам записей за миллисекунды.
Использование
Для начала вам нужно будет создать индекс. Для этого нужно описать схему документа. Поля, не описанные в схеме, не будут индексироваться, но будут доступны в результатах поиска.
import { create, insert } from '@lyrasearch/lyra';
const movieDB = create({
schema: {
title: 'string',
director: 'string',
plot: 'string',
year: 'number',
isFavorite: 'boolean'
}
});
На текущий момент Lyra версии
0.3умеет искать только по строковым полям, так что остальные поля описывать в схеме бесполезно. Если верить официальной документции то такая возможность может появиться в будущем.
То есть в описании схемы можно ограничиться только следующим.
import { create, insert } from '@lyrasearch/lyra';
const movieDB = create({
schema: {
title: 'string',
director: 'string',
plot: 'string'
}
});
Далее вставить в него документы.
const { id: thePrestige } = insert(movieDB, {
title: 'The prestige',
director: 'Christopher Nolan',
plot: 'Two friends and fellow magicians become bitter enemies after a sudden tragedy. As they devote themselves to this rivalry, they make sacrifices that bring them fame but with terrible consequences.',
year: 2006,
isFavorite: true
});
const { id: bigFish } = insert(movieDB, {
title: 'Big Fish',
director: 'Tim Burton',
plot: 'Will Bloom returns home to care for his dying father, who had a penchant for telling unbelievable stories. After he passes away, Will tries to find out if his tales were really true.',
year: 2004,
isFavorite: true
});
Также есть метод для пакетной вставки документов insertBatch.
Для поиска по подготовленному индексу можно воспользоваться методом search. Подробнее про параметры поиска можно прочитать в документации.
const searchResult = search(movieDB, {
term: "Harry",
properties: "*",
});
Эксперимент
Для того чтобы потестировать эту библиотеку я нашел датасет русских анекдотов на 26Мб, 124155 документов. Мне показалось, что это неплохой размер данных для serverless поиска. Если у вас данных больше, то наверняка вам �стоит задуматься об использовании нормального инструмента, а не мастерить велосипеды.
Итак, для начала я импортировал датасет в индекс Lyra и посмотрел, сколько он будет занимать в сериализованном виде.
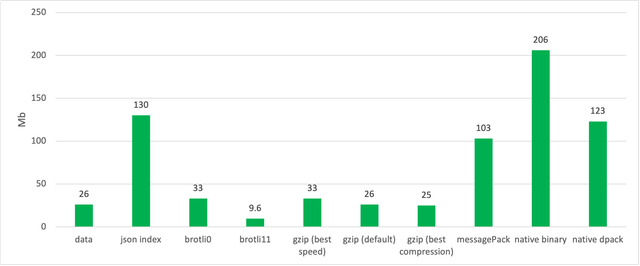
Как видно из графика индекс сериализованный в JSON занимает 130Mb. Lyra предоставляет плагин для сериализации. Кроме jsonтам есть binary(206Mb) и dpack(123Mb) форматы. И вроде dpackчуть меньше, но очевидно, что можно получить результат лучше. Для этого я пожал JSON разными популярными алгоритмами сжатия.
Почему именно они? Потому что они есть в стандартной библиотеке Node.js zlib.
Почему я не стал рассматривать сжатие binary и dpack? Потому что кроме размера получаемого артефакта я также посмотрел на время его десереализации. Данные получены на моем ноутбуке, так что стоит смотреть скорее не на абсолюты, а на относительную разницу.
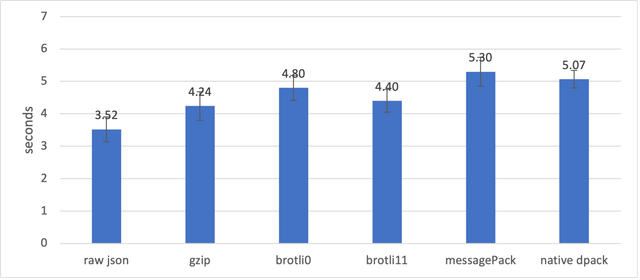
Как видно большую часть времени занимает именно построение объекта индекса, что даже добавление распаковки из архива не сильно сказывается на общем времени. При этом бинарные форматы проигрывают JSON. Он отлично оптимизирован. Именно поэтому я не стал экспериментировать с дополнительным их сжатием, так как это только увеличило бы их отставание от JSON.
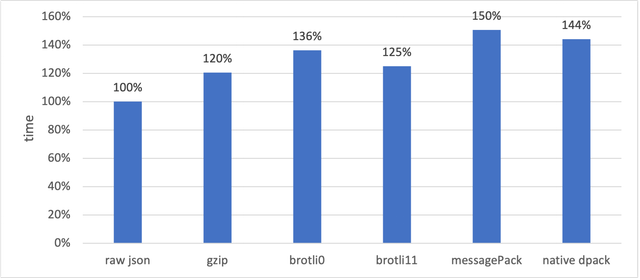
Теперь посмотрим на время сжатия. Эта метрика важна для нас если мы хотим иметь не статический индекс, а обновлять его периодически.
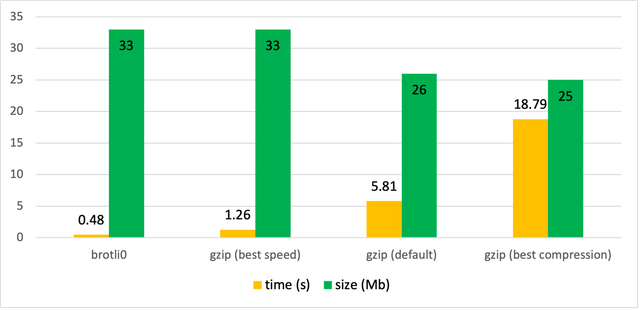
Как видно brotli с минимальной степенью сжатия 0 дает тот же самый размер, что и gzip в режиме приоритета скорости, при этом всё равно выигрывая его в два с половиной раза по скорости. Более высокие степени сжатия хоть и дают меньший размер артефакта сильно проигрывают в скорости. Как вы могли заметить на график не попал brotli11 с максимальной степенью сжатия 11. Это потому что на текущем индексе сжатие занимало 4.5–5 минут, хотя и давало наименьший результат. Этот вариант я могу рекомендовать лишь для статических индексов, где нет необходимости обновления, а значит затрат на их обновление.
Для дальнейших исследований я выберу gzip (как вариант для обновляемых индексов) и brotli11 (вариант для статики), чтобы сравнить, как размер сериализованного индекса скажется на времени холодного старта функции.
Кроме представленных форматов я рассматривал еще и Protobuf. Но к сожалению он не поддерживает вложенные словари, а формат индекса их активно использует. В итоге у меня получилось написать сериализатор, но проигрывал в скорости JSON, требовал дополнительно описывать структуру индекса и в итоге не попал в сравнение.
Функция
import {GetObjectCommand, S3} from "@aws-sdk/client-s3";
import {create, Data, load, Lyra, search} from "@lyrasearch/lyra";
import {stemmer} from "@lyrasearch/lyra/dist/cjs/stemmer/lib/ru.js";
import {Handler} from '@yandex-cloud/function-types'
import {Stream} from "stream";
import * as zlib from "zlib";
let db: Lyra<{ joke: "string" }> | null = null;
const accessKeyId = process.env.AWS_ACCESS_KEY_ID;
const secretAccessKey = process.env.AWS_SECRET_ACCESS_KEY;
if (accessKeyId === undefined || secretAccessKey === undefined) {
throw new Error("missing env variables")
}
const s3Client = new S3({
forcePathStyle: false, // Configures to use subdomain/virtual calling format.
endpoint: "https://storage.yandexcloud.net",
region: "ru-central1",
credentials: {
accessKeyId,
secretAccessKey,
}
});
// Specifies a path within your bucket and the file to download.
const bucketParams = {
Bucket: "sls-search",
Key: "index"
};
// Function to turn the file's body into a string.
const streamToData = (stream: Stream): Promise<Data<{ joke: "string" }>> => {
const chunks: any[] = [];
const gz = zlib.createGunzip();
stream.pipe(gz);
console.log("pipe")
return new Promise((resolve, reject) => {
gz.on('data', (chunk) => chunks.push(Buffer.from(chunk)));
gz.on('error', (err) => reject(err));
gz.on('end', () => resolve(JSON.parse(Buffer.concat(chunks).toString())));
});
};
// Downloads your file and saves its contents to /tmp/local-file.ext.
const loadDb = async () => {
try {
console.log("start loading")
const response = await s3Client.send(new GetObjectCommand(bucketParams));
const data = await streamToData(response.Body as Stream) as Data<{ joke: "string" }>;
load(db!, data);
console.log("loaded")
return data;
} catch (err) {
console.log("Error", err);
}
};
export async function loadAndSearch(term: string): Promise<object> {
if (db === null) {
db = await create({
edge: true,
defaultLanguage: "russian",
schema: {
joke: "string",
},
tokenizer: {
stemmingFn: stemmer,
},
});
await loadDb();
}
console.log("try to search")
const res = search(db, {
term,
properties: ["joke"],
})
return {
code: 200,
body: {
...res,
elapsed: `${res.elapsed}`
}
};
}
// @ts-ignore
export const handler: Handler.Http = async (event, context): Promise<object> => {
const term = event.queryStringParameters["term"];
return await loadAndSearch(term);
};
Кажется код достаточно понятен. На первом старте индекс будет подгружен из Object Storage и десериализован. Поэтому холодный старт будет, в нашем случае не очень маленького индекса, около 5 секунд.
Подводные камни
Так же я наступил в ошибку: загрузка приводит к ошибке аллокации памяти Reached heap limit Allocation failed — JavaScript heap out of memory. Несмотря на то, что при создании версии ее было выделено достаточно (2Гб), функция падает в районе потребления 256Мб.
<--- Last few GCs --->
[8:0x4cc6180] 3469 ms: Mark-sweep (reduce) 254.6 (256.6) -> 254.3 (256.9) MB, 11.0 / 0.0 ms (+ 4.0 ms in 228 steps since start of marking, biggest step 2.6 ms, walltime since start of marking 84 ms) (average mu = 0.950, current mu = 0.859) allocation
[8:0x4cc6180] 3486 ms: Mark-sweep (reduce) 255.3 (256.9) -> 255.3 (257.9) MB, 12.3 / 0.0 ms (average mu = 0.899, current mu = 0.283) allocation failure scavenge might not succeed
<--- JS stacktrace --->
FATAL ERROR: Reached heap limit Allocation failed - JavaScript heap out of memory
В принципе, решение этой проблемы довольно легко гуглится: нужно передать node.js флаг --max-old-space-size=2048, где число — количество мегабайт выделяемой памяти. Не самыми очевидными были следующие шаги — как передать его, чтобы он надежно подхватился рантаймом? Скажу честно, их мне подсказали в поддержке:
- Этот флаг можно передать через переменную окружения
NODE_OPTIONS. Но это не решает проблему до конца, так как последняя версия Node-рантаймаnodejs16является предзагружаемой — это значит, что для нее применяются оптимизации, которые позволяют значительно уменьшить время холодного старта. К сожалению, они приводят к тому, что вы можете получить рантайм из пула предсозданных, а значит ключи изNODE_OPTIONSк нему не применятся. - Оптимизация холодного старта актуальна в случае обычных функций, у которых время исполнения измеряется десятками миллисекунд. Наша же функция на первом старте в любом случае грузит индекс, так что выигрышем в пары сотен миллисекунд на первом старте мы можем пожертвовать. Они не будут заметны на фоне остального времени старта в 5 секунд. Поэтому мы можем применить второй флаг, отключающий эту оптимизацию:
YCF_NO_RUNTIME_POOL=1
Давайте посмотрим на результаты стрельб Танком.
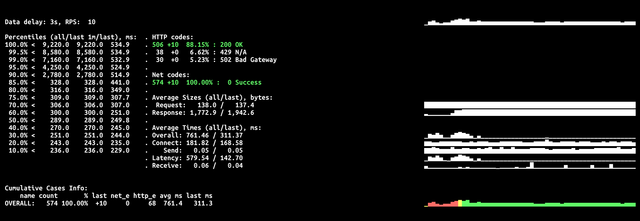
YCF_NO_RUNTIME_POOL=1Как видно из результатов, часть рантаймов досталась нам из пула и это привело к 502 ошибкам. Ошибки 429 — это слишком активно отсылаемые Танком запросы в тот момент пока создаются инстансы рантаймов и не было достаточно ресурсов чтобы их обработать.
После отключения рантайм пула картина следующая.
Теперь если посмотреть на результаты времени поиска в индексе, то типичными значениями будут 30–50мс, а общее время выполнения запроса 250–300мс. На мой взгляд очень неплохо.
Обновление индекса
Перестроение индекса можно организовать в функции вызываемой по cron-триггеру, она будет вычитывать обновления из БД и дописывать их и индекс, а затем заливать его в S3.
В случае же, если вам не нужно обновлять данные, то их можно попробовать положить рядом с кодом функции. Это позволит избавиться от лишних походов в S3, тем самым выиграть еще немного на холодном старте.
Ну и напоследок ссылка на live demo от авторов и репозиторий с кодом примера.
UPD: Если вам, как и мне, казалось, что время «холодного» старта можно улучшить, то про это я расскажу в следующем посте. Правда там будет уже не JavaScript, а Go.